


Potencjalnym ryzykiem może być obarczony proces, który sam w sobie jeszcze nie stanowi naruszenia przepisów prawa ochrony danych osobowych jednak w wyniku braku postępowania z tym ryzykiem może on być przyczyną powstania

Odbierz pakiet bezpłatnych poradników i mikroszkoleń RODO
niezgodności. Przykładowo pozyskiwanie danych osobowych potencjalnych klientów bez wymaganej zgody na prowadzenia marketingu bezpośredniego drogą elektroniczną (np. mailing) sam w sobie nie jest jeszcze niezgodnością. Jednak kolejnym krokiem w powyższym procesie będzie wysyłka niezamówionych informacji handlowych drogą elektroniczną co już jest dużą niezgodnością.
„Kto przesyła za pomocą środków komunikacji elektronicznej niezamówione informacje handlowe, podlega karze grzywny"[1]
Innymi słowy ryzykiem będzie działanie administratora danych, które wraz z upływem czasu może doprowadzić do niezgodności, dużej lub małej. Identyfikacja potencjalnych ryzyk wymaga czujność i umiejętności przewidywania kolejnych zdarzeń przez ABI/IOD z tego też powodu większość początkujących ABI nie sięga do takich narzędzi pracy jak klasyfikacja ryzyka.
Istnieje wiele metod szacowania ryzyka jednak przy przeprowadzaniu pierwszego szacowania ryzyka ochrony danych osobowych warto rozważyć zastosowanie poniższej metody. Poniżej schemat pokazujący proces szacowania ryzyka.
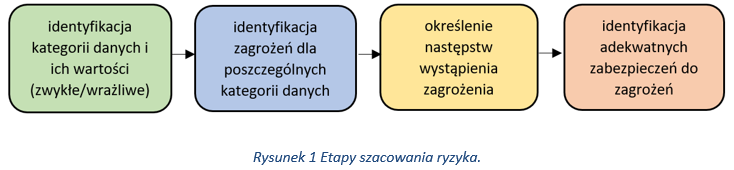
Pierwszy etap jako identyfikacja kategorii danych musi pojawić się ze względu na przepisy prawa, wiec ten etap jest najprostszy, gdyż rozróżniamy dane ze względu na ich kategorię (tzw. zwykłe i wrażliwe). W kolejnym etapie musimy zidentyfikować istniejące zagrożenia, jednak by to zrobić musimy wiedzieć gdzie się znajdują dane i w jakiej formie się one znajdują elektroniczna czy papierowa. Jak już wiemy gdzie są dane, musimy określić występujące zagrożenia. W tym miejscu musimy dokonać indywidualnej oceny co może się stać z danymi w konkretnym obszarze np. kradzież, spalenie, zalanie, etc. Kolejno oceniamy jak utrata konkretnej kategorii danych w konkretnym procesie wpłynie na całą organizację np. krytyczne procesy zostaną zatrzymane, dojdzie do zerwania umów przez klientów, dojdzie do kontroli GIODO i konsekwencji z niej wynikających. Tu nieuchronnie należy dokonać klasyfikacji zidentyfikowanych ryzyk, czyli określić czy wysokość ryzyka w stosunku do poszczególnego procesu. Poniżej przykładowa tabela klasyfikacji ryzyka:
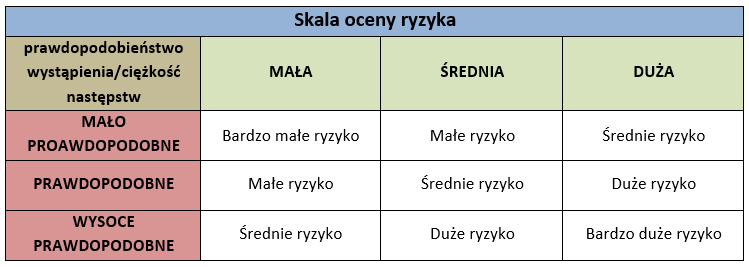
Korzystając z powyższej tabeli możemy określić, że konkretny proces zostaje zaklasyfikowany jako stwarzający bardzo małe ryzyko, małe ryzyko, średnie ryzyko, duże ryzyko lub bardzo duże ryzyko.
Ostatecznie wynikiem całego procesu jest określenie jakie działania wobec ryzyk powinny zostać podjęte, czyli np. jakie zabezpieczenia muszą być zastosowane by uniknąć negatywnych konsekwencji w stosunku do konkretnej kategorii danych, która znajduje się w konkretnej lokalizacji. Postępowanie z ryzykiem może się sprowadzać do następujących działań:
- obniżanie ryzyka poprzez wdrażanie dodatkowych zabezpieczeń,
- pozostawienie ryzyka na poziomie określonym w procesie szacowania ryzyka i zaniechanie dalszych działań,
- unikanie ryzyka przez niepodejmowanie działań będących źródłem ryzyka,
- przeniesienie ryzyka na inny podmiot w zakresie odpowiedzialności za zarządzanie ryzykiem bez możliwości przeniesienia odpowiedzialności za skutki wynikające z naruszenia poufności, integralności lub dostępności danych osobowych.

E-learning RODO to już standard!
Powyższy proces może wydawać się złożony i faktycznie w niektórych przypadkach tak jest np. ocena ryzyka przetwarzania danych wrażliwych, powierzonych przez klientów znajdujących się na serwerze, którym administruje podmiot zewnętrzny. Jednak w innym przypadku proces ten może być banalnie prosty np. ocena ryzyka danych zwykłych w postaci księgi wejść i wyjść, znajdującej się na recepcji, a po godzinach pracy zamykanej na klucz nie stwarza już znacznego problemu.
Czytaj także: Szacowanie ryzyka zgodnie z RODO - cz. 1
Wraz z rozpoczęciem obowiązywania przepisów RODO, administrator danych będzie musiał przeprowadzać ocenę skutków przetwarzania danych osobowych przed rozpoczęciem procesu przetwarzania danych osobowych, czyli w praktyce będzie musiał oceniać zgodność przyszłego planowanego stanu faktycznego. Z tego względu warto już teraz powoli zdobywać doświadczenie w identyfikacji ryzyk przetwarzania danych osobowych.
„Jeżeli dany rodzaj przetwarzania – w szczególności z użyciem nowych technologii – ze względu na swój charakter, zakres, kontekst i cele z dużym prawdopodobieństwem może powodować wysokie ryzyko naruszenia praw lub wolności osób fizycznych, administrator przed rozpoczęciem przetwarzania dokonuje oceny skutków planowanych operacji przetwarzania dla ochrony danych osobowych. Dla podobnych operacji przetwarzania danych wiążących się z podobnym wysokim ryzykiem można przeprowadzić pojedynczą ocenę.”[2]
Podsumowanie
Proces analizy ryzyka może być bardzo złożony ale może być również bardzo prosty. Wszystko zależy od tego jakie założenia w tym procesie przyjmiemy. Warto pamiętać o definicji ryzyka „Możliwość zaistnienia zdarzenia, które będzie miało wpływ na realizację założonych celów. Ryzyko jest mierzone wpływem (skutkami) i prawdopodobieństwem wystąpienia”.
--
[1] Art. 24 ust. 1 Ustawy z dnia 18 lipca 2002r. o świadczeniu usług drogą elektroniczną (Dz.U. 2002 nr 144 poz. 1204 z zm.)
[2] Art. 35 ust. 1 Rozporządzenia Parlamentu Europejskiego i Rady (UE) 2016/679 z dnia 27 kwietnia 2016 r. w sprawie ochrony osób fizycznych w związku z przetwarzaniem danych osobowych i w sprawie swobodnego przepływu takich danych oraz uchylenia dyrektywy 95/46/WE (ogólne rozporządzenie o ochronie danych)
