


Niezależnie od skali działalności, każda organizacja objęta obowiązkami NIS2, określonymi w ustawie o krajowym systemie cyberbezpieczeństwa (KSC), może wykorzystać politykę zarządzania incydentami jako narzędzie do lepszego zarządzania ryzykiem, zwiększenia odporności na cyberzagrożenia i podniesienia poziomu bezpieczeństwa cyfrowego. W tym artykule przyjrzymy się, jakie korzyści niesie wdrożenie tej polityki oraz jakie elementy powinna ona zawierać, aby była skuteczna i zgodna z nowymi regulacjami.

Polityka zarządzania incydentami
Zgodnie ustawą o KSC / NIS2, podmioty kluczowe i ważne są zobowiązane do opracowania i wdrożenia polityki zarządzania incydentami, która jasno określa role, odpowiedzialności oraz procedury związane z wykrywaniem incydentów, ich analizą, ograniczaniem ich skutków, reagowaniem na nie, odzyskiwaniem stanu sprzed ich wystąpienia, dokumentowaniem tych incydentów oraz raportowaniem ich w odpowiednim czasie.
Polityka ta powinna mieć jasno zdefiniowane cele i być zgodna z obowiązującymi przepisami prawa, regulacjami oraz standardami branżowymi, takimi jak ISO/IEC 27001 czy wytyczne ENISA. Zasadnicze znaczenie ma uwzględnienie w niej standardów i dobrych praktyk, które organizacja przyjęła jako podstawę swojego działania. W ramach zgodności organizacja powinna posiadać udokumentowaną politykę, która szczegółowo opisuje wymagane elementy oraz procedury. Ważnym aspektem jest również doprecyzowanie zakresu odpowiedzialności oraz przypisanie ról w organizacji, aby zapewnić efektywne reagowanie na incydenty. Tak opracowana polityka nie tylko pozwala spełnić wymagania regulacyjne, lecz także minimalizuje ryzyko i potencjalne straty wynikające z incydentów, co wzmacnia odporność organizacji na cyberzagrożenia.
Polityka zarządzania incydentami jako filar ciągłości działania i planu odzyskiwania po awarii
Polityka zarządzania incydentami jest filarem systemu zarządzania bezpieczeństwem informacji. Powinna ona być spójna z planem ciągłości działania (Business Continuity Plan – BCP) oraz planem odzyskiwania po awarii (Disaster Recovery Plan – DRP). Pozwala to organizacjom skutecznie reagować na incydenty w sposób minimalizujący ich wpływ na działalność operacyjną i infrastrukturę IT. Aby zapewniać kompleksowe zarządzanie incydentami, polityka ta musi jednak zawierać określone elementy.
Elementy polityki zarządzania incydentami
- System kategoryzacji incydentów
Polityka powinna określać spójny system kategoryzacji incydentów. Taka kategoryzacja pozwala na szybkie określenie priorytetu incydentu oraz na adekwatne dostosowanie działań naprawczych.
- Plany komunikacyjne, w tym procedury eskalacji i raportowania
Właściwa komunikacja w sytuacjach kryzysowych to podstawa skutecznego zarządzania incydentami. Polityka powinna zawierać szczegółowe plany komunikacyjne, które określają, w jaki sposób i do kogo eskalować incydenty, a także wskazują zasady raportowania do organów nadzoru lub innych właściwych podmiotów.
- Przypisanie ról i odpowiedzialności
Polityka musi jasno wskazywać, którzy pracownicy są odpowiedzialni za wykrywanie incydentów i reakcję na nie. Ważne jest, aby te role były przypisane kompetentnym i przeszkolonym osobom, które dysponują wiedzą oraz narzędziami niezbędnymi do szybkiego i skutecznego działania.
- Dokumenty wspierające proces zarządzania incydentami
Skuteczne zarządzanie incydentami wymaga posiadania odpowiednich dokumentów, takich jak:
- podręczniki reagowania na incydenty – opisujące krok po kroku procedury działania w przypadku różnych scenariuszy,
- schematy eskalacji – ułatwiające szybką identyfikację odpowiednich osób lub zespołów, które powinny zostać zaangażowane na danym etapie,
- listy kontaktowe – umożliwiające szybki dostęp do danych osób odpowiedzialnych za reagowanie na incydenty,
- szablony dokumentów – upraszczające i przyspieszające proces raportowania incydentów oraz komunikacji z odpowiednimi podmiotami.

System kategoryzacji incydentów
Ważną częścią polityki zarządzania incydentami jest system kategoryzacji incydentów. Powinien on pozwalać na identyfikację konsekwencji incydentu oraz na priorytetyzację zdarzeń na podstawie jasno określonych kryteriów. Przykładowe kryteria to:
- wpływ na działalność biznesową,
- klasyfikacja danych zgodnie z RODO,
- wpływ prawny i regulacyjny,
- zakres i skala incydentu,
- typ ataku (np. malware, ransomware),
- krytyczność dotkniętych systemów,
- pilność ograniczenia skutków incydentu,
- możliwość odzyskania danych,
- wpływ na życie i bezpieczeństwo ludzi.
Rodzaje incydentów objęte polityką zarządzania incydentami
Polityka powinna uwzględniać różne typy incydentów, takie jak:
- awaria systemów i utrata dostępności usług,
- złośliwe oprogramowanie,
- ataki typu denial of service (DoS),
- błędy systemowe i błędy użytkownika,
- naruszenia poufności i integralności danych,
- nadużycie systemów sieciowych i informatycznych.
Plan komunikacji incydentów
Efektywna komunikacja w sytuacjach kryzysowych jest niezbędna do skutecznego zarządzania incydentami. Plan komunikacji powinien zawierać:
- cel i zakres planu,
- role i odpowiedzialności za zadania komunikacyjne,
- listę interesariuszy wewnętrznych i zewnętrznych, którzy powinni zostać poinformowani,
- warunki i procedury eskalacji incydentów,
- kanały komunikacji (e-mail, intranet, telefony, media społecznościowe, komunikaty prasowe),
- możliwości zbierania opinii lub pytań od interesariuszy,
- wytyczne dotyczące terminów komunikacji i częstotliwości aktualizacji,
- gotowe szablony wiadomości na różne scenariusze.
Kluczowe elementy skutecznej polityki zarządzania incydentami w powiązaniu z ciągłością działania i odzyskiwaniem po awarii
Efektywna polityka zarządzania incydentami powinna być spójnie zintegrowana z planem ciągłości działania (BCP) oraz planem odzyskiwania po awarii (DRP). Taka integracja umożliwia organizacjom lepsze przygotowanie na różnorodne zagrożenia i na minimalizowanie ich skutków.
Najważniejsze elementy, które powinny być udokumentowane i wdrożone
- Powiązania między polityką zarządzania incydentami a planami BCP i DRP
Polityka powinna odnosić się do procesów i procedur zawartych w planie ciągłości działania i planie odzyskiwania po awarii. Taka integralność gwarantuje ich wzajemne uzupełnianie i spójność operacyjną.
- Rejestry testów i symulacji
Regularne testy i ćwiczenia uwzględniające zarówno procesy zarządzania incydentami, jak i plan ciągłości działania oraz plan odzyskiwania po awarii są podstawą do zapewnienia skuteczności wszystkich elementów.
- Wywiady z kluczowymi osobami
Rozmowy z pracownikami odpowiedzialnymi za reagowanie na incydenty, ciągłość działania i odzyskiwanie po awarii pozwalają ocenić, czy polityka jest zrozumiała i stosowana w praktyce.
- System kategoryzacji incydentów
Każda organizacja powinna posiadać jasno zdefiniowany system kategoryzacji incydentów. Taki system umożliwia szybką ocenę priorytetu zdarzenia i jego wpływu na działalność oraz pozwala na wskazanie wymaganych działań.

- Dowody wdrożenia polityki zarządzania incydentami
Dokumentacja powinna potwierdzać, że polityka zarządzania incydentami została opracowana, wdrożona oraz zakomunikowana wszystkim pracownikom.
- Plan komunikacji incydentów
Organizacja powinna dysponować szczegółowym planem komunikacji dotyczącym zarządzania incydentami, obejmującym m.in. kanały komunikacji, procedury eskalacji oraz gotowe szablony komunikatów.
- Procedury komunikacji z odpowiednimi organami i CSIRT
Polityka powinna określać kroki niezbędne do zgłoszenia incydentu odpowiednim organom regulacyjnym oraz zespołom reagowania na incydenty bezpieczeństwa komputerowego (CSIRT).
- Procedury komunikacji z klientami i dostawcami
W przypadku incydentów, które mogą wpłynąć na klientów lub wymagają zaangażowania dostawców, polityka powinna wskazywać, w jaki sposób i kiedy należy ich poinformować, przy zapewnieniu transparentności i efektywności działań.
Testowanie i przeglądanie polityki zarządzania incydentami
Regularne testowanie ról, odpowiedzialności i procedur określonych w polityce zarządzania incydentami ma podstawowe znaczenie dla utrzymania ich efektywności i zgodności z aktualnym krajobrazem zagrożeń. Zaleca się, aby testy odbywały się przynajmniej dwa razy w roku, a przeglądy były przeprowadzane co najmniej raz na 12 miesięcy.
Metody testowania polityki zarządzania incydentami
Testowanie polityki zarządzania incydentami może przyjąć różne formy w zależności od specyfiki organizacji i poziomu ryzyka. Wśród rekomendowanych metod warto wyróżnić:
- ćwiczenia tabletop – skuteczną metodę oceny spójności procedur i poziomu świadomości zespołu, polegającą na teoretycznych symulacjach sytuacji kryzysowej, podczas których uczestnicy omawiają swoje role i działania krok po kroku,
- symulację incydentu – praktyczne odtworzenie ataku lub sytuacji kryzysowej, oparte na zidentyfikowanych ryzykach i bieżących zagrożeniach, pozwalające na weryfikację reakcji organizacji w realistycznych warunkach,
- ćwiczenia red team/blue team – scenariusz zakładający symulację ataku (red team) i obrony (blue team), dzięki czemu można testować zarówno reakcje na incydent, jak i skuteczność systemów ochrony,
- analizę logów – przegląd zapisów systemowych w celu zidentyfikowania śladów potencjalnych incydentów, ich źródeł oraz efektywności wdrożonych procedur monitorowania,
- odtwarzanie wcześniejszych incydentów – analizę krok po kroku incydentów, które wydarzyły się w przeszłości, pozwalającą ocenić skuteczność działań naprawczych oraz wdrożonych polityk.
Zakres przeglądu ról, odpowiedzialności i procedur
Przegląd ról, odpowiedzialności i procedur powinien być przeprowadzany co najmniej raz w roku. W trakcie aktualizacji warto uwzględnić:
- wyniki przeprowadzonych testów – analizę rezultatów zebranych podczas ćwiczeń, co pozwala wskazać obszary wymagające korekt lub usprawnień,
- zmiany w krajobrazie zagrożeń – nowe techniki ataków, zmieniające się zagrożenia oraz rosnącą złożoność środowiska IT, aby dostosować procedury do aktualnych realiów,
- wymagania prawne i regulacyjne – zmiany w przepisach dotyczących bezpieczeństwa sieci i systemów informacyjnych oraz regulacjach branżowych,
- zmiany w politykach organizacyjnych – wszelkie zmiany w politykach bezpieczeństwa wewnętrznego w celu ich skoordynowania z procedurami zarządzania incydentami.

OFERTA PROMOCYJNA
Zarządzanie incydentami bezpieczeństwa
Chcesz wdrożyć skuteczny system zarządzania incydentami w swojej organizacji? Skonsultuj się z nami i otrzymaj indywidualną propozycję wdrożenia
Przykłady dowodów skutecznego testowania i przeglądania polityki zarządzania incydentami
Dokumentowanie realizacji polityki zarządzania incydentami ma fundamentalne znaczenie w zapewnieniu zgodności z wymaganiami regulacyjnymi oraz w ocenie gotowości organizacji do reakcji na potencjalne zagrożenia. Skuteczność działań w tym obszarze mogą potwierdzać następujące dowody:
- dokumentacja okresowych symulacji i działań podnoszących świadomość – regularne symulacje incydentów oraz szkolenia personelu pozwalają ocenić poziom gotowości zespołu oraz adekwatność stosowanych procedur, co może mieć odzwierciedlenie w raportach z ćwiczeń, scenariuszach symulacji lub harmonogramach szkoleń,
- plany i harmonogramy testowania polityki zarządzania incydentami – istotnym elementem potwierdzającym wdrożenie polityki zarządzania incydentami jest dokumentacja zawierająca harmonogramy testów, opis planowanych ćwiczeń oraz raporty z realizacji testów,
- plany i harmonogramy przeglądów polityki zarządzania incydentami – kluczowymi dowodami na dbanie o aktualność procedur oraz o ich zgodność z obowiązującymi wymaganiami są przeglądy polityki zarządzania incydentami, przeprowadzane zgodnie z ustalonym harmonogramem, wraz z wynikami analizy, wnioskami i zaleceniami usprawnień.
Gromadzenie powyższych dowodów pozwala nie tylko na weryfikację skuteczności procedur, lecz także na dokumentowanie zgodności z regulacjami prawnymi i standardami bezpieczeństwa.
Monitorowanie i rejestrowanie aktywności w infrastrukturze IT
Monitorowanie i logowanie działań w systemach informacyjnych oraz sieciach organizacji to podstawowe czynności pozwalające na wykrywanie potencjalnych incydentów oraz na szybkie reagowanie na zagrożenia. Prawidłowo wdrożone procedury monitorowania wspierają zarówno bezpieczeństwo, jak i optymalizację działania systemów.
Cele monitorowania aktywności
Dzięki monitorowaniu aktywności organizacja może realizować różne cele w zależności od swoich potrzeb. Wśród najważniejszych celów monitorowania można wyróżnić:
- wykrywanie zagrożeń – identyfikację nieautoryzowanych działań oraz potencjalnych ataków,
- zapewnienie zgodności (compliance) – monitorowanie przestrzegania procedur i regulacji prawnych,
- wsparcie reakcji na incydenty – rejestrację zdarzeń, które mogą posłużyć jako podstawa do szybkiej interwencji,
- optymalizację wydajności – analizę danych w celu poprawy działania systemów i sieci,
- wykrywanie anomalii – identyfikację nieprawidłowych wzorców zachowań i działań,
- ochronę przed utratą danych (Data Loss Prevention) – monitorowanie aktywności mającej na celu zapobieganie wyciekom danych,
- monitorowanie stanu sieci – bieżącą kontrolę wydajności i bezpieczeństwa sieci.
Opis procedur monitorowania
Procedury dotyczące monitorowania powinny obejmować:
- cele – określenie jasnych i mierzalnych celów monitorowania, takich jak wykrywanie incydentów czy poprawa wydajności,
- zakres zbieranych danych – wskazanie, jakie informacje będą monitorowane (np. logi systemowe, ruch sieciowy, zachowanie użytkowników),
- analizę algorytmów danych – metody przetwarzania i interpretacji zgromadzonych danych,
- mechanizmy powiadamiania – ustalenie sposobów informowania odpowiednich osób lub zespołów o wykrytych incydentach i nieprawidłowościach.
Wybór narzędzi monitorujących
Skuteczne monitorowanie wymaga używania odpowiednich narzędzi, które spełniają określone kryteria. Przy ich wyborze warto uwzględnić:
- łatwość użytkowania – intuicyjność interfejsu i dostępność funkcjonalności dla personelu,
- integrację z istniejącymi systemami – możliwość połączenia z aktualną infrastrukturą IT organizacji,
- minimalizację interwencji manualnych – automatyzację zbierania i analizy danych,
- zdolność zbierania danych z różnych źródeł – obsługę logów sieciowych, aplikacyjnych czy systemowych,
- funkcje zabezpieczeń – szyfrowanie, kontrolę dostępu oraz mechanizmy ochrony danych,
- koszty i licencjonowanie – analizę kosztów wdrożenia i utrzymania narzędzi.

Przykłady dowodów monitorowania i rejestrowania aktywności
Wdrożenie skutecznych procedur monitorowania i rejestrowania aktywności wymaga posiadania odpowiedniej dokumentacji oraz dowodów potwierdzających realizację założonych celów. Przykłady takich dowodów obejmują:
- istnienie procedur – formalne procedury monitorowania i rejestrowania są wdrożone i dostępne dla zespołów odpowiedzialnych za bezpieczeństwo,
- narzędzia do monitorowania i logowania – organizacja posiada odpowiednie narzędzia umożliwiające zbieranie, analizowanie oraz raportowanie aktywności w systemach sieciowych i informacyjnych,
- ustawienia konfiguracyjne – konfiguracja funkcji logowania jest dostosowana do określonych celów monitorowania, takich jak wykrywanie zagrożeń, analiza wydajności czy zapobieganie utracie danych,
- zgodność z normami i dobrymi praktykami – ustawienia funkcji logowania są zgodne z obowiązującymi standardami oraz najlepszymi praktykami w zakresie bezpieczeństwa informacji,
- mechanizmy ochrony logów – wdrożone są zabezpieczenia zapewniające poufność, integralność i dostępność logów, takie jak szyfrowanie, kontrola dostępu oraz mechanizmy redundancji.
Automatyzacja monitorowania i minimalizacja błędów
Automatyzacja monitorowania systemów informatycznych oraz sieci jest kluczowa dla zapewnienia skuteczności procesu wykrywania incydentów i reagowania na nie. Proces ten, prowadzony w sposób ciągły lub cykliczny, powinien być dostosowany do możliwości organizacyjnych i skoncentrowany na minimalizacji błędów typu false positives (fałszywych alarmów) oraz false negatives (przeoczonych zagrożeń).
Wytyczne dotyczące optymalizacji monitorowania
Aby ograniczyć liczbę fałszywych alarmów i nieprawidłowo wykrywanych incydentów, zaleca się:
- wykorzystanie algorytmów analitycznych i uczenia maszynowego – zaawansowane algorytmy mogą analizować duże zbiory danych, wykrywać wzorce oraz redukować ryzyko błędnej identyfikacji incydentów,
- ciągłe aktualizowanie narzędzi monitorujących – systemy monitorujące powinny być regularnie dostosowywane do nowych zagrożeń oraz zmieniających się warunków w środowisku IT,
- optymalizowanie parametrów i progów detekcji – precyzyjne dostrojenie ustawień monitorowania na podstawie aktualnych danych i opinii zespołów bezpieczeństwa pozwala na zwiększenie dokładności identyfikacji incydentów.
Przykłady dowodów skuteczności systemu monitorowania
Organizacje mogą potwierdzić skuteczność wdrożonego systemu monitorowania przez następujące dowody:
- zgodność z najnowszymi standardami technologicznymi – narzędzia monitorujące, rejestrujące i analizujące dane są zgodne z najlepszymi praktykami oraz aktualnym stanem wiedzy technicznej,
- wykorzystanie systemów SIEM – zaawansowane systemy zarządzania informacjami i zdarzeniami bezpieczeństwa (SIEM) analizują dane, wykrywają anomalie oraz identyfikują odchylenia od ustalonych bazowych wzorców,
- mechanizmy redukujące błędy – wdrożone rozwiązania, takie jak automatyczne filtrowanie i korelacja zdarzeń, skutecznie minimalizują fałszywe alarmy i ryzyko pominięcia incydentów.
Zakres logowania aktywności w systemach informacyjnych
Zgodnie z ustalonymi procedurami monitorowania i logowania organizacje są zobowiązane do utrzymywania, dokumentowania oraz przeglądania logów. Lista aktywów podlegających logowaniu powinna zostać opracowana na podstawie wyników analizy ryzyka. W zależności od potrzeb logi powinny obejmować następujące kategorie:
- ruch sieciowy wychodzący i przychodzący – rejestrowanie komunikacji w sieciach organizacji w celu monitorowania i analizowania zagrożeń,
- tworzenie, modyfikacja i usuwanie użytkowników – zmiany w kontach użytkowników oraz rozszerzenia uprawnień w systemach i sieciach informacyjnych,
- dostęp do systemów i aplikacji – rejestrowanie prób dostępu użytkowników do zasobów organizacji oraz działań związanych z takim dostępem,
- zdarzenia związane z uwierzytelnianiem – rejestrowania informacji dotyczących logowania, wylogowania oraz prób autoryzacji,
- uprzywilejowany dostęp – działania wykonywane przez konta administracyjne oraz uprzywilejowane w systemach i aplikacjach,
- dostęp do konfiguracji i plików kopii zapasowych – logowanie zmian w kluczowych konfiguracjach oraz plikach backupowych,
- logi z narzędzi zabezpieczających – zapisy z systemów zabezpieczeń, takich jak antywirusy, IDS/IPS czy zapory sieciowe,
- wykorzystanie zasobów systemowych – monitorowanie wykorzystania zasobów, takich jak procesor, pamięć oraz wydajność aplikacji,
- fizyczny dostęp do obiektów – rejestrowanie prób fizycznego dostępu do pomieszczeń lub urządzeń organizacji oraz zdarzeń związanych z takim dostępem,
- dostęp do urządzeń sieciowych – logowanie prób konfiguracji urządzeń sieciowych oraz korzystania z tych urządzeń,
- aktywacja, zatrzymanie i pauzowanie logów – rejestrowanie zdarzeń związanych z zarządzaniem procesami logowania,
- zdarzenia środowiskowe – monitorowanie informacji związanych ze środowiskiem, takich jak awarie zasilania czy zmiany w warunkach pracy systemów.

Konfiguracja krytyczna i znaczenie logów
Konfiguracje krytyczne mają kluczowe znaczenie dla prawidłowego funkcjonowania, bezpieczeństwa oraz wydajności systemów sieciowych i informacyjnych organizacji. Każda zmiana lub błędna konfiguracja może prowadzić do poważnych konsekwencji. Takimi negatywnymi skutkami są na przykład:
- awaria systemów – nieprawidłowe parametry mogą prowadzić do przerw w działaniu usług,
- luki w zabezpieczeniach – błędne ustawienia stanowią zagrożenie dla bezpieczeństwa informacji,
- obniżona wydajność systemów – niewłaściwe parametry wpływają na stabilność i efektywność działania sieci oraz aplikacji.
Przykłady dowodów prawidłowej konfiguracji krytycznej
Dowody potwierdzające skuteczność zarządzania konfiguracją krytyczną oraz logowaniem obejmują co najmniej pliki logów zawierające wymagane elementy (dokumentujące krytyczne zmiany).
Analiza logów i progi alarmowe
Regularna analiza logów oraz progi ustawione dla alarmów są najważniejszymi czynnikami w wykrywaniu anomalii oraz przeciwdziałaniu zagrożeniom w systemach sieciowych i informacyjnych. Wartości progowe powinny być dostosowane do wyników analizy ryzyka i automatycznie wywoływać alerty, gdy zostaną przekroczone, co pozwala na szybką reakcję i minimalizację potencjalnych skutków.
Wytyczne dotyczące analizy logów i alarmów
- Wykrywanie ataków sieciowych
Wykrywanie ataków sieciowych pozwala na identyfikację nieprawidłowych wzorców ruchu przychodzącego i wychodzącego oraz ataków typu DoS (Denial of Service) w odpowiednim czasie.
- Ustawienie progów alarmowych
Wartości progowe powinny być zgodne z wynikami analizy ryzyka i uwzględniać najczęściej występujące zagrożenia. Przykłady sytuacji objętych progami to:
- ruch sieciowy – nagłe skoki ruchu przekraczające 50% normalnego poziomu w ciągu 10 minut na określonym porcie,
- dostęp do systemów – trzy zablokowane próby logowania lub więcej w ciągu 15 minut,
- dostęp uprzywilejowany – dwa przypadki eskalacji uprawnień lub więcej (np. zmiana użytkownika na administratora) w ciągu 24 godzin,
- antywirus – trzy wykrycia złośliwego oprogramowania na różnych urządzeniach lub więcej w ciągu 30 minut,
- zasoby systemowe – trzy instalacje nieautoryzowanego oprogramowania lub więcej w ciągu 30 minut.
Przykłady dowodów skutecznego analizowania logów i alarmów
Organizacje mogą wykazać skuteczność wdrożonych mechanizmów analizowania logów i alarmów przez następujące dowody:
- regularne raporty – podsumowania analizy logów zawierające wykryte anomalie,
- ustawione progi alarmowe – dokumentacja progów dla kluczowych zdarzeń oraz analiza ich efektywności,
- historia aktywacji alarmów – zapisy dotyczące wcześniejszych przypadków przekroczenia wartości progowych i wywołania alertów,
- istniejące procesy raportowania zdarzeń – potwierdzone ścieżki eskalacji w przypadku aktywacji alarmów.
Przechowywanie, zabezpieczanie i usuwanie logów
Skuteczne zarządzanie logami obejmuje określenie czasu ich przechowywania, zabezpieczenie przed nieautoryzowanym dostępem oraz odpowiednie usunięcie danych po zakończeniu okresu retencji.
Wytyczne dotyczące przechowywania logów
- Okres przechowywania logów

Kiedy ostatnio
robiłeś analizę ryzyka?
- Logi zapasowe (backup)
Logi zapasowe muszą być przechowywane przez okres nie krótszy niż czas wymagany do przeglądu logów.
- Usuwanie danych
Dane powinny być usuwane automatycznie po zakończeniu zdefiniowanego okresu retencji, aby zapewnić zgodność z zasadą minimalizacji danych.
Mechanizmy ochrony logów
Aby zabezpieczyć logi przed nieautoryzowanym dostępem lub modyfikacją, zaleca się wdrożenie następujących mechanizmów:
- szyfrowanie – ochrona logów za pomocą zaawansowanych technik szyfrowania,
- kontrola dostępu – ograniczenie uprawnień do odczytu, modyfikacji oraz usuwania logów tylko do upoważnionych osób,
- haszowanie – zastosowanie funkcji haszujących w celu zapewnienia integralności logów i wykrywania nieautoryzowanych zmian,
- rejestrowanie dostępu i zmian w logach – prowadzenie szczegółowych zapisów dotyczących wszelkich działań związanych z logami (odczyt, modyfikacja, usunięcie).
Zgodność z regulacjami
Mechanizmy kontroli dostępu i retencji danych powinny zapewniać pełną przejrzystość oraz audytowalność działań.
Przykłady dowodów skutecznego zarządzania logami
Wdrożenie odpowiednich mechanizmów zarządzania logami można potwierdzić za pomocą następujących dowodów:
- ustawiony okres retencji – zdefiniowany czas przechowywania logów jest zgodny z wymaganiami organizacyjnymi i regulacyjnymi,
- zgodność okresu retencji z regulacjami – okres przechowywania logów nie jest krótszy niż okres ich przeglądu,
- centralne zarządzanie logami – wdrożony scentralizowany system logowania umożliwia jednolite gromadzenie i monitorowanie logów,
- brak danych po upływie okresu retencji – logi nie zawierają danych, których czas przechowywania dobiegł końca,
- mechanizmy kontroli dostępu – zabezpieczenia ograniczają dostęp do logów wyłącznie do upoważnionych osób i procesów.
Synchronizacja czasu oraz redundancja systemów logowania
W celu zapewnienia dokładnej korelacji logów oraz ich dostępności organizacje muszą wdrożyć mechanizmy synchronizacji czasu i redundancji systemów monitorowania. Precyzyjnie zsynchronizowane źródła czasu oraz redundantne systemy są konieczne do skutecznej analizy zdarzeń i minimalizacji ryzyka utraty danych.
Wytyczne dotyczące synchronizacji czasu
- Wykorzystanie protokołów NTP i PTP
Organizacja powinna stosować Network Time Protocol (NTP) lub Precision Time Protocol (PTP) w celu dokładnej synchronizacji czasu między systemami.
- Uwierzytelniony NTP
Zastosowanie uwierzytelnionego NTP zapobiega manipulacjom czasem przez nieautoryzowane podmioty.
- Centralny serwer czasu
Centralny serwer czasu jest skonfigurowany tak, że synchronizuje się z zewnętrznym, wiarygodnym źródłem i rozprowadza czas do wszystkich systemów w sieci.
- Wielokrotne źródła czasu
Użycie kilku niezależnych źródeł synchronizacji czasu minimalizuje ryzyko awarii spowodowanej pojedynczym punktem błędu.
Wytyczne dotyczące redundancji systemów logowania
- Redundantne przechowywanie logów
Logi powinny być przechowywane w redundantnych lokalizacjach (np. chmura, serwery zapasowe), aby zapobiec utracie danych.
- Monitoring systemów logowania
Niezależne narzędzia powinny monitorować stan oraz dostępność głównych systemów monitorowania i logowania.
- Inwentaryzacja aktywów
Wszystkie aktywa podlegające logowaniu powinny być oznaczone w rejestrze aktywów.
Przykłady dowodów skuteczności synchronizacji czasu i redundancji systemów logowania
Skuteczność synchronizacji czasu i redundancji systemów logowania można potwierdzić następującymi dowodami:
- wdrożone i działające poprawnie mechanizmy synchronizacji czasu logów,
- redundantne przechowywanie logów w wielu lokalizacjach,
- logi z narzędzi monitorujących dostępność i zdrowie głównych systemów logowania oraz monitorowania.
Przegląd procedur i listy logowanych aktywów
Regularny przegląd procedur i listy logowanych aktywów podlegających logowaniu jest niezbędny do zapewnienia aktualności i skuteczności systemu monitorowania. Przeglądy powinny być realizowane na podstawie wyników analizy ryzyka, ze szczególnym uwzględnieniem krytyczności aktywów.
Częstotliwość przeprowadzania przeglądów procedur i listy logowanych aktywów
Organizacja powinna określić, jak często należy dokonywać przeglądów procedur i listy logowanych aktywów, biorąc pod uwagę wyniki analizy ryzyka oraz krytyczność poszczególnych aktywów. Przeglądy powinny być przeprowadzane co najmniej raz w roku lub po wystąpieniu istotnych incydentów.
Przykłady dowodów skuteczności przeglądów procedur i listy logowanych aktywów
Skuteczność przeglądów procedur i listy logowanych aktywów mogą potwierdzić plany lub harmonogramy tych przeglądów, zawierające terminy ich przeprowadzenia oraz ich zakres.
Zgłaszanie zdarzeń
Organizacje powinny wdrożyć prosty i skuteczny mechanizm umożliwiający pracownikom, dostawcom oraz klientom zgłaszanie podejrzanych zdarzeń.
Wytyczne dotyczące zgłaszania zdarzeń
- Definicja podejrzanego zdarzenia
Zdarzenie uznaje się za podejrzane, jeśli spełnia jedno z poniższych kryteriów:
- narusza poufność, integralność lub dostępność sieci lub systemu informacyjnego,
- ma charakter ciągły (zdarzenie jest aktywne lub trwałe),
- wpływa na znaczną liczbę zasobów, generuje straty finansowe lub wywołuje inne konsekwencje dla organizacji,
- stanowi naruszenie zgodności z regulacjami prawnymi lub wewnętrznymi politykami organizacji.
- Zakres raportowania zdarzeń
Organizacja powinna opracować przejrzyste wymagania dotyczące informacji zawartych w zgłoszeniu. Minimalny zakres zgłoszenia obejmuje:
- datę i godzinę zdarzenia,
- opis zdarzenia – w tym jego charakter i potencjalne skutki,
- dowody – zrzuty ekranu, logi lub inne istotne materiały,
- dane kontaktowe osoby zgłaszającej, przekazane w celu dalszej komunikacji.
- Kanały raportowania
Mechanizm zgłaszania zdarzeń powinien obejmować różne łatwo dostępne i intuicyjne kanały, takie jak:
- e-mail,
- formularz internetowy,
- specjalna infolinia,
- aplikacja mobilna.
Przykłady dowodów zgłaszania zdarzeń
Organizacja może potwierdzić skuteczność mechanizmu zgłaszania zdarzeń za pomocą następujących dowodów:
- udokumentowany mechanizm zgłaszania zdarzeń – formalny proces określający kroki raportowania incydentów bezpieczeństwa,
- przykłady lub szablony raportów – dostępne wzory dokumentów usprawniające zgłaszanie podejrzanych zdarzeń,
- świadomość personelu – potwierdzenie, że pracownicy wiedzą, jak działa mechanizm i do kogo należy zgłaszać podejrzane zdarzenia,
- wiele kanałów zgłaszania – dokumentacja potwierdzająca dostępność różnych kanałów komunikacji, takich jak adresy e-mail, formularze internetowe, numery telefonów, specjalne portale raportowania.
Komunikacja i szkolenia w zakresie mechanizmu zgłaszania zdarzeń
Organizacje powinny skutecznie informować swoich pracowników, dostawców i klientów o mechanizmie zgłaszania zdarzeń, a także zapewniać im regularne szkolenia z użytkowania tego mechanizmu.

Wytyczne dotyczące komunikacji i szkoleń w zakresie mechanizmu zgłaszania zdarzeń
- Należy udostępnić wszystkim interesariuszom (pracownikom, dostawcom, klientom) odpowiednie środki i terminy odnoszące się do raportowania zdarzeń.
- Należy rozważyć opcję anonimowego zgłaszania, aby zachęcić do raportowania incydentów bez obawy przed konsekwencjami.
- Należy uwzględnić obowiązki prawne dotyczące terminów zgłaszania incydentów do właściwych organów.
- Należy przypominać o mechanizmie zgłaszania za pomocą różnych kanałów komunikacji, takich jak newslettery, plakaty czy inne środki informacyjne.
- Należy organizować ćwiczenia i symulacje w celu testowania skuteczności mechanizmu zgłaszania oraz poziomu gotowości personelu.
Przykłady dowodów skutecznej komunikacji i szkoleń w zakresie mechanizmu zgłaszania zdarzeń
Skuteczność działań związanych z komunikacją i szkoleniami w zakresie mechanizmu zgłaszania zdarzeń mogą potwierdzać:
- dowody wcześniejszych komunikatów dotyczących zgłaszania zdarzeń,
- udokumentowane procedury komunikacji, zawierające: powody zgłaszania incydentów (biznesowe, prawne), typy zdarzeń objętych raportowaniem, wymagane treści komunikatów, kanały raportowania, role i odpowiedzialności związane z komunikacją oraz zgłaszaniem incydentów,
- materiały szkoleniowe dostarczone pracownikom, dostawcom i klientom,
- symulacje i ćwiczenia oceniające gotowość personelu oraz skuteczność mechanizmu raportowania zdarzeń.
Ocena podejrzanych zdarzeń i ich klasyfikacja
Organizacje powinny wdrożyć mechanizmy oceny podejrzanych zdarzeń, aby określić, czy stanowią one incydenty, oraz ustalić ich charakter i poziom powagi.
Wytyczne dotyczące oceny zdarzeń
- Kryteria oceny zdarzeń
Wykorzystanie zdefiniowanych kryteriów umożliwia ocenę, czy podejrzane zdarzenie kwalifikuje się jako incydent.
- Klasyfikacja incydentów
Określenie natury i poziomu powagi incydentu powinno być oparte na systemie kategoryzacji.
Przykłady dowodów skutecznej oceny zdarzeń
O skutecznej ocenie zdarzeń mogą świadczyć następujące dowody:
- zdefiniowane kryteria – formalnie przyjęte zasady oceny podejrzanych zdarzeń,
- system kategoryzacji incydentów – mechanizm umożliwiający klasyfikację incydentów według ich charakteru, skali i wpływu na organizację.
Działania związane z oceną i klasyfikacją podejrzanych zdarzeń
- Przeprowadzenie oceny
Ocena zdarzeń powinna być realizowana zgodnie z wcześniej zdefiniowanymi kryteriami, z uwzględnieniem priorytetyzacji działań związanych z ograniczeniem skutków i eliminacją incydentu (triage).
- Ocena powtarzających się incydentów
Organizacja powinna kwartalnie analizować przypadki występowania powtarzających się incydentów.
- Przegląd logów
Logi związane z incydentami powinny być systematycznie przeglądane w celu dokładnej oceny oraz klasyfikacji zdarzeń.
- Proces korelacji i analizy logów
Wdrożenie procesu umożliwiającego korelację oraz analizę logów pozwala na wykrywanie wzorców oraz związków między zdarzeniami, co wspiera skuteczność oceny incydentów.
- Ponowna ocena i klasyfikacja zdarzeń
W przypadku uzyskania nowych informacji lub wyników analizy dostępnych danych organizacja powinna ponownie ocenić i sklasyfikować zdarzenia, aby zapewnić ich właściwą identyfikację i priorytetyzację.

Procedury oceny podejrzanych zdarzeń i klasyfikacji incydentów
Organizacje powinny udokumentować procedury oceny podejrzanych zdarzeń, aby określić ich charakter i poziom powagi.
Etapy procedury oceny podejrzanych zdarzeń
- Zbieranie informacji i dowodów
Gromadzenie istotnych informacji i materiałów związanych ze zdarzeniem.
- Analiza wpływu zdarzenia
Ocena potencjalnych skutków dla systemów, danych i operacji organizacji.
- Określenie poziomu powagi incydentu
Klasyfikacja zdarzenia na podstawie wcześniej zdefiniowanych kryteriów.
Wytyczne dotyczące klasyfikacji incydentów i reakcji na nie
- Stosowanie playbooków i runbooków
Należy opracować gotowe scenariusze reakcji na typowe incydenty, takie jak ransomware, phishing, utrata danych czy pożar.
- Klasyfikacja zdarzeń
Zdarzenia powinny być klasyfikowane na podstawie:
- poziomu skutków – poziom niski, średni lub wysoki,
- typu incydentu – np. infekcja złośliwym oprogramowaniem, nieautoryzowany dostęp,
- wymiaru zgodności regulacyjnej – potencjalne naruszenie przepisów lub wymagań.
- Priorytetyzacja incydentów
Priorytet zdarzenia ustala się na podstawie kryteriów zawartych w systemie kategoryzacji.
- Identyfikacja powtarzających się incydentów
w celu określenia, czy incydent ma charakter powtarzalny, wykonuje się analizę przyczyn źródłowych (root cause analysis).
- Przegląd i korelacja logów
Logi powinny być analizowane i korelowane.
- Ocena przeszłych incydentów
Klasyfikacja historycznych incydentów pozwala na usprawnienie procesów, procedur i progów reagowania.
Przykłady dowodów oceny zdarzeń i klasyfikacji incydentów
Organizacja może potwierdzić skuteczność procesu oceny zdarzeń oraz klasyfikacji incydentów przez następujące dowody:
- udokumentowane procedury lub wytyczne dotyczące oceny zdarzeń – opis takich czynności, jak zbieranie informacji, przeprowadzenie analizy wpływu, określenie poziomu powagi incydentu,
- kryteria priorytetyzacji zdarzeń – dokumentacja opisująca zasady klasyfikacji zdarzeń na podstawie ich powagi oraz potencjalnego wpływu,
- proces triage – wdrożony system priorytetyzacji alertów i raportów dotyczących podejrzanych zdarzeń,
- playbooki dla typowych incydentów – gotowe scenariusze działań dla często występujących typów incydentów (np. ransomware, phishing),
- okresowe przeglądy oceny zdarzeń – regularne analizy historycznych incydentów oraz ich klasyfikacji w celu usprawnienia procesów, procedur i progów reagowania.
Procedury reagowanie na incydenty
Organizacje powinny wdrożyć procedury skutecznego reagowania na incydenty. Zapewniają one szybkie i zgodne z ustalonymi standardami działania w sytuacjach kryzysowych.
zne dotyczące testowania procedur reag
Wytyczne dotyczące reagowania na incydenty
- Zespół reagowania na incydenty (Incident Response Team)
Należy utworzyć specjalny zespół składający się z pracowników posiadających odpowiednią wiedzę techniczną oraz uprawnienia do skutecznego reagowania na incydenty.
- Określenie ról i odpowiedzialności
W zespole należy zdefiniować i przypisać role, takie jak:
- koordynatorzy incydentów,
- analitycy,
- osoby odpowiedzialne za komunikację i współpracę z interesariuszami.
- Uwzględnienie znanych standardów
Procedury reagowania na incydenty powinny być opracowane z uwzględnieniem uznanych standardów, np. ISO 27035.
Przykłady dowodów skutecznego reagowania na incydenty
Dowody skutecznego reagowania na incydenty obejmują:
- przypisanie ról i odpowiedzialności w ramach zespołu reagowania na incydenty,
- udokumentowane standardy oraz dobre praktyki uwzględnione przy tworzeniu procedur reakcji na incydenty.
Etapy procedury reagowania na incydenty
- Izolacja incydentu

RODO.
Wsparcie się przydaje
- Usunięcie zagrożenia
Organizacja powinna zastosować środki zapobiegające kontynuacji incydentu lub ponownemu wystąpieniu incydentu.
- Odzyskiwanie po incydencie
Odzyskiwanie po incydencie, jeśli jest to konieczne, polega na wdrożeniu procesów przywracających normalne funkcjonowanie organizacji.
Wytyczne dotyczące szczegółowych procedur reagowania na incydenty
- Opracowanie szczegółowych procedur reagowania na incydenty
Należy przygotować jasne i precyzyjne procedury postępowania w razie różnych rodzajów incydentów.
- Uwzględnienie priorytetów organizacji
Podczas obsługi incydentów cyberbezpieczeństwa należy uwzględniać priorytety organizacji oraz wpływ danego incydentu.
- Rozwiązywanie konfliktów priorytetów
Właściwe reagowanie na incydenty wymaga balansowania między:
- działaniami zabezpieczającymi dowody w sposób gwarantujący ich wiarygodność i przydatność w dochodzeniach lub procesach prawnych.
- działaniami reakcyjnymi eliminującymi istniejące zagrożenia,
- działaniami operacyjnymi IT, które mają na celu minimalizację wpływu incydentu.
Decyzje dotyczące rozwiązywania konfliktów powinny być przedstawione organom zarządzającym.
Przykłady dowodów skutecznego reagowania na incydenty
Skuteczność reagowania na incydenty można ocenić na podstawie następujących dowodów:
- procedury reagowania na incydenty – dokumentacja zawierająca szczegółowe kroki, typy incydentów, role i odpowiedzialności, działania zarządzające i eskalacyjne,
- zapisy dotyczące rozwiązywania konfliktów priorytetów podczas wcześniejszych incydentów.
Plany i procedury komunikacji w przypadku incydentów
Organizacje powinny opracować szczegółowe plany i procedury komunikacji dotyczące incydentów, aby zapewnić właściwe powiadamianie odpowiednich podmiotów i interesariuszy.
Wytyczne dotyczące komunikacji w przypadku incydentów
- Komunikacja z CSIRT oraz właściwymi organami
Procedury powinny określać sposób zgłaszania incydentów do zespołów reagowania na incydenty bezpieczeństwa komputerowego (CSIRT) oraz, jeśli to konieczne, do właściwych organów nadzorczych i władz kompetentnych.
- Komunikacja z interesariuszami
Plany komunikacji muszą uwzględniać wewnętrznych i zewnętrznych interesariuszy, w tym:
- kluczowych pracowników,
- partnerów biznesowych,
- klientów,
- dostawców, jeśli ich zaangażowanie jest konieczne.
- Informacje kontaktowe
Procedury powinny zawierać zaktualizowane dane kontaktowe dla kluczowych osób, interesariuszy zewnętrznych oraz właściwych organów.
Przykłady dowodów skutecznej komunikacji w przypadku incydentów
Skuteczna komunikacja podczas incydentów może być udokumentowana przez:
- procedury komunikacji określające sposób zgłaszania incydentów do właściwych organów oraz CSIRT,
- procedury komunikacji z klientami i dostawcami, ze wskazaniem, kiedy i w jaki sposób ich zaangażować.
Rejestrowanie działań związanych z reagowaniem na incydenty
Organizacje powinny prowadzić szczegółowy zapis działań podejmowanych w ramach reagowania na incydenty zgodnie z obowiązującymi procedurami.
Dzienniki incydentów powinny zawierać co najmniej następujące informacje:
- czas poszczególnych etapów – wykrycia, izolacji, eliminacji zagrożenia,
- moment przywrócenia systemów do pełnej funkcjonalności,
- wskaźniki kompromitacji (IoCs) – dowody potwierdzające naruszenie,
- przyczyna źródłowa (root cause) – analiza powodu wystąpienia incydentu,
- działania podjęte w każdej fazie – wykrycie, izolacja i eliminacja,
- ocena skutków incydentu dla organizacji,
- komunikacja prowadzona w trakcie reakcji na incydent,
- wnioski i rekomendacje wynikające z analizy incydentu,
- zgłoszenie incydentu do CSIRT lub właściwych organów.
Przykłady dowodów działań związanych z reagowaniem na incydenty
Dowodami na podjęcie działań związanych z reagowaniem na incydenty mogą być dzienniki incydentów, czyli szczegółowe zapisy dokumentujące przebieg danego incydentu i kluczowe momenty reakcji na ten incydent.
Testowanie procedur reagowania na incydenty
Organizacje powinny regularnie testować swoje procedury reagowania na incydenty, aby upewnić się, że są skuteczne i odpowiednio przygotowane na różne rodzaje zagrożeń.

Wytyczne dotyczące testowania procedur reagowania na incydenty
- Częstotliwość testów
Procedury reagowania na incydenty powinny być testowane co najmniej raz w roku.
- Rodzaje testowanych incydentów
Scenariusze testowe powinny obejmować różne typy incydentów, takie jak:
- ransomware,
- phishing,
- wyciek danych (data breach),
- ataki typu DoS (Denial of Service).
- Zaangażowanie interesariuszy
Testy powinny uwzględniać pracowników z różnych działów oraz zewnętrznych interesariuszy, takich jak dostawcy usług czy partnerzy biznesowi.
- Udział kadry zarządzającej
Zarząd powinien brać udział w testach, aby zrozumieć swoją rolę podczas faktycznego incydentu.
- Ocena testów i aktualizacja procedur
Po zakończeniu testów należy przeprowadzić przegląd wyników w celu wyciągnięcia wniosków i wdrożenia niezbędnych usprawnień w procedurach.
Przykłady dowodów skutecznego testowania procedur reagowania na incydenty
Dowody świadczące o efektywnym testowaniu procedur reagowania na incydenty to między innymi:
- plany i harmonogramy testów – dokumentacja planowanych testów reagowania na incydenty,
- zapisy z przeprowadzonych testów – szczegółowe raporty z testów różnych typów incydentów, zawierające wnioski oraz rekomendacje.
Przeglądy po incydencie i analiza przyczyn źródłowych
Po zakończeniu działań naprawczych związanych z incydentem organizacje powinny przeprowadzić przeglądy po incydencie (post-incident reviews), aby zidentyfikować przyczyny źródłowe, czynniki wpływające na wystąpienie incydentu oraz możliwości usprawnienia procesów.
Wytyczne dotyczące przeglądów po incydencie
- Definiowanie procesu przeglądu po incydencie
Należy opracować i wdrożyć proces przeprowadzania przeglądów po zakończeniu incydentów bezpieczeństwa.
- Identyfikacja przyczyn źródłowych
Analiza powinna uwzględniać:
- przyczyny źródłowe (root cause),
- czynniki przyczyniające się do wystąpienia incydentu,
- obszary wymagające usprawnień w zakresie wykrywania incydentu, reagowania na ten incydent i odzyskiwania po incydencie.
- Badanie znaczących incydentów
Dla poważnych incydentów należy przygotować końcowe raporty, zawierające:
- opis podjętych działań,
- rekomendacje mające na celu zapobieganie podobnym incydentom w przyszłości.
- Dokumentowanie wniosków
Wnioski z przeglądów powinny być udokumentowane na podstawie logów i analiz działań podejmowanych w ramach reagowania na incydent.
Przykłady dowodów skutecznych przeglądów po incydencie
Skuteczność przeglądu po incydencie można potwierdzić przez:
- analizy przyczyn źródłowych (root cause analysis) – dokumenty identyfikujące przyczynę incydentu,
- raporty z obsługi istotnych incydentów – szczegółowe opisy podjętych działań oraz rekomendacje na przyszłość,
- udokumentowane wnioski i lekcje wyniesione z incydentów – raporty zawierające obszary usprawnień oraz dobre praktyki do wdrożenia.

Analiza przeglądów po incydencie i wdrożenie usprawnień
Organizacje powinny potwierdzić, że przeglądy po incydentach przyczyniają się do ulepszania podejścia do bezpieczeństwa sieciowego i informacyjnego, działań zarządzania ryzykiem oraz procedur związanych z obsługą, wykrywaniem i reagowaniem na incydenty.
Wytyczne dotyczące analizy przeglądów po incydencie i usprawnień
- Należy analizować wyniki przeglądów po incydencie w celu zidentyfikowania luk i słabych punktów w systemie bezpieczeństwa organizacji.
- Należy upewnić się, że zidentyfikowane problemy są uwzględnione w procesie oceny ryzyka oraz w planach zarządzania ryzykiem.
- Należy ocenić, czy istniejące środki zarządzania ryzykiem były skuteczne w zapobieganiu lub łagodzeniu skutków incydentu.
- Należy sporządzić kompletne raporty z przeglądów, zawierające wnioski i rekomendacje na przyszłość.
- Należy sprawdzić, czy spełniono wymagania bezpieczeństwa informacji podczas obsługi incydentu, i w razie potrzeby podjąć odpowiednie działania naprawcze.Przykłady dowodów skutecznej analizy po incydencie
Dowody świadczące o przeprowadzeniu rzetelnej analizy po incydencie to na przykład:
- raporty przeglądów po incydentach – dokumentujące wnioski, zidentyfikowane luki i rekomendacje usprawnień,
- komunikowanie działań naprawczych – analiza, rozwiązania oraz środki zaradcze przekazywane odpowiednim członkom zespołu.
Regularne przeglądy przeglądów po incydencie
Organizacje powinny przeprowadzać regularne przeglądy przeglądów po incydencie, aby ocenić, czy incydenty skutkowały odpowiednimi analizami i wnioskami oraz czy zostały wdrożone działania naprawcze.
Wytyczne dotyczące przeglądów przeglądów po incydencie
Należy przeprowadzić roczne przeglądy lub przeglądy po znaczących incydentach, aby zweryfikować:
- czy przeprowadzono przegląd po incydencie,
- jakie wnioski i rekomendacje wyniknęły z przeglądu,
- czy zidentyfikowane usprawnienia zostały wdrożone.
Przykłady dowodów skutecznych przeglądów przeglądów po incydencie
Dowodami na to, że organizacja skutecznie analizuje i ocenia przeprowadzone przeglądy po incydencie, są udokumentowane plany lub harmonogramy przyszłych przeglądów, potwierdzające ich regularność i planowanie.
Sprawdź co pamiętasz - za poprawną odpowiedź nagroda!
Który z poniższych elementów jest kluczowy dla skutecznej polityki zarządzania incydentami w powiązaniu z planami ciągłości działania (BCP) i odzyskiwania po awarii (DRP)?
Od czego zacząć wdrożenie ustawy o KSC / NIS2?
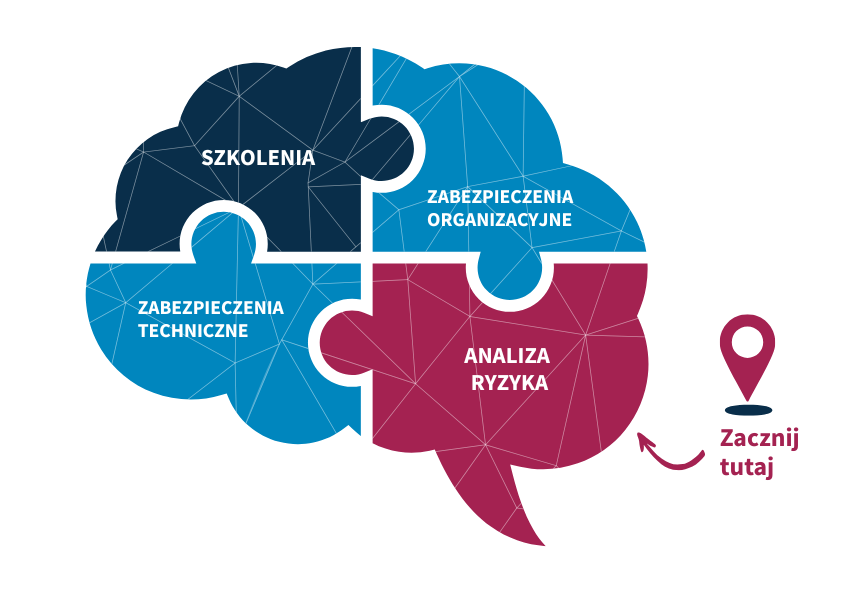
Wdrożenie KSC / NIS2 należy rozpocząć od analizy ryzyka – to pierwszy i kluczowy krok, który pozwala zidentyfikować zasoby, zagrożenia oraz luki w zabezpieczeniach.
Dlaczego to takie ważne?
Wymogi NIS2 określone w ustawie o KSC, podobnie jak RODO, nie precyzują konkretnych środków ochrony – to Ty, na podstawie przeprowadzonej analizy ryzyka, musisz określić adekwatne środki zabezpieczeń.
Kolejne kroki wdrożenia KSC / NIS2 to:
1. Zabezpieczenia techniczne
Inwestycje w konkretne technologie i narzędzia ochronne. Ustawa o KSC / NIS2 wymaga realnego, „twardego" bezpieczeństwa, a nie tylko dokumentacji.
2. Zabezpieczenia organizacyjne
Opracowanie i wdrożenie procedur wymaganych przez KSC / NIS2. Dzięki nim pracownicy będą wiedzieli, jak bezpiecznie działać w ramach infrastruktury IT.
3. Szkolenia
Regularna edukacja pracowników i zarządu, która zapewni świadomość ról, obowiązków i zasad bezpieczeństwa. To bezpośredni wymóg KSC / NIS2.
Podsumowując: zacznij od analizy ryzyka, a dopiero potem zadbaj o odpowiednie zabezpieczenia techniczne, organizacyjne i szkolenia.