


Ciągłość działania i szybkie odzyskiwanie po awarii to obecnie fundamenty bezpieczeństwa organizacji, szczególnie w obliczu rosnących zagrożeń cybernetycznych i ryzyk operacyjnych. Dyrektywa NIS2 została implementowana do prawa polskiego poprzez nowelizację ustawy o krajowym systemie cyberbezpieczeństwa. Ustawa ta zwana ustawą o KSC, wprowadza nowe obowiązki dla podmiotów kluczowych i ważnych, wymaga od organizacji opracowania i utrzymania planu ciągłości działania (Business Continuity Plan – BCP) oraz planu odzyskiwania po awarii (Disaster Recovery Plan – DRP).

Dlaczego zapewnienie ciągłości działania jest takie ważne
Incydenty mogą mieć różne źródła – od klęsk żywiołowych po awarie technologiczne czy cyberataki. Każda przerwa w działaniu kluczowych usług oznacza straty finansowe, operacyjne i wizerunkowe. Planowanie ciągłości działania pozwala organizacjom nie tylko przetrwać kryzys, lecz także działać stabilnie w dłuższej perspektywie.
Jak stworzyć skuteczny plan ciągłości działania i plan odzyskiwania po awarii
-
Postaw na sprawdzone standardy
Opracowanie planu nie musi być wymyślaniem koła na nowo. Warto skorzystać z uznanych międzynarodowych standardów, takich jak ISO 22301 dla ciągłości działania czy ITIL dla zarządzania incydentami. Dzięki temu działania będą spójne i mierzalne.
-
Identyfikuj zagrożenia i krytyczne zdarzenia
Stwórz listę potencjalnych zdarzeń, które mogą zakłócić Twoje usługi. Nie zapominaj o:
- klęskach naturalnych (powodziach, pożarach),
- awariach infrastruktury IT,
- atakach cybernetycznych (np. ransomware),
- przerwaniu łańcuchów dostaw.
-
Zaplanuj mechanizmy odzyskiwania
W skutecznym planie muszą się znaleźć konkretne zasoby i działania:
- kopie zapasowe – określ, gdzie będą przechowywane dane i jak często będą tworzone ich kopie,
- testy odzyskiwania – regularnie sprawdzaj skuteczność procedur,
- cele czasowe – zdefiniuj kluczowe wskaźniki, jak Recovery Time Objective (RTO) i Recovery Point Objective (RPO).
Jakie dowody spełnienia wymagań warto przygotować
Aby udowodnić zgodność z wymogami NIS2, organizacja powinna dysponować następującymi dokumentami:
- planem ciągłości działania (BCP),
- planem odzyskiwania po awarii (DRP),
- dokumentacją potwierdzającą zgodność działań ze standardami lub najlepszymi praktykami,
- listą zidentyfikowanych zagrożeń i przypisanych mechanizmów odzyskiwania.

Jakie są najważniejsze elementy planu ciągłości działania i planu odzyskiwania po awarii
Zgodnie z wytycznymi NIS2 operacje organizacji powinny być przywracane zgodnie z planem ciągłości działania (BCP) oraz planem odzyskiwania po awarii (DRP). Plany te muszą opierać się na wynikach oceny ryzyka, aby skutecznie minimalizować skutki zakłóceń.
W dobrze przygotowanym planie powinny zostać uwzględnione następujące elementy:
-
Cel, zakres i odbiorcy planu
Określ główny cel planu oraz jego zakres – które procesy i systemy obejmuje. Zdefiniuj, kto jest odbiorcą planu: zarząd, kadra kierownicza czy konkretne zespoły operacyjne.
-
Role i odpowiedzialności
Wskaż osoby odpowiedzialne za konkretne etapy wdrażania i realizacji planu. Ustal hierarchię oraz zakres odpowiedzialności poszczególnych członków zespołu reagowania kryzysowego.
-
Kluczowe kontakty i kanały komunikacji
Przygotuj listę kluczowych kontaktów – zarówno wewnętrznych (zespoły IT, zarząd), jak i zewnętrznych (dostawcy usług, partnerzy, organy regulacyjne). Wyznacz kanały komunikacji do użytku w sytuacjach kryzysowych, takie jak telekonferencje, bezpieczne aplikacje komunikacyjne czy stałe punkty kontaktu.
-
Warunki aktywacji i dezaktywacji planu
Sprecyzuj, w jakich okolicznościach plan zostaje uruchomiony. Określ kryteria zakończenia działań naprawczych i przejścia na normalne procedury operacyjne.
-
Kolejność przywracania operacji
Ustal priorytety działań: które systemy, procesy lub usługi powinny być przywracane w pierwszej kolejności, aby zminimalizować przestoje i straty. Przykładowo usługi krytyczne, takie jak systemy transakcyjne, powinny być przywrócone przed mniej istotnymi funkcjami.
-
Plany odzyskiwania dla konkretnych operacji
Stwórz szczegółowe plany odzyskiwania dla każdego kluczowego procesu. Zdefiniuj cele odzyskiwania, takie jak:
- Recovery Time Objective (RTO) – czas potrzebny na przywrócenie operacji,
- Recovery Point Objective (RPO) – dopuszczalna utrata danych.
-
Wymagane zasoby
Uwzględnij wszystkie zasoby niezbędne do realizacji planu, w tym kopie zapasowe, redundancje, zapasowe systemy oraz narzędzia wsparcia technicznego.
-
Przywracanie działalności i tymczasowe środki
Opisz procedury przywracania normalnych operacji po zastosowaniu tymczasowych rozwiązań. Zdefiniuj kroki umożliwiające płynne przejście od działań awaryjnych do stabilnej pracy organizacji.

OFERTA PROMOCYJNA
Przygotuj się do KSC / NIS2
Potrzebujesz wsparcia w dostosowaniu organizacji do wymogów NIS2 określonych w ustawie o KSC? Podczas konsultacji omówimy Twoje potrzeby i zaproponujemy dedykowane rozwiązania
Jak efektywnie wdrożyć plan ciągłości działania i plan odzyskiwania po awarii
Zapewnienie ciągłości działania i odzyskiwania po awarii to podstawowy wymóg NIS2. Wytyczne ENISA podkreślają konieczność planowania, monitorowania i wdrażania zaawansowanych rozwiązań, które pozwolą organizacjom szybko reagować na incydenty i minimalizować zakłócenia w dostępie do usług krytycznych.
Aby spełnić te wymogi, należy podjąć następujące działania:
-
Monitorowanie i dokumentowanie realizacji planu
Wdrożenie planu ciągłości działania wymaga systematycznego prowadzenia dziennika jego realizacji. Dziennik powinien opisywać:
- podjęte decyzje,
- kroki wykonane w procesie,
- finalny czas odzyskania pełnej operacyjności.
Tak przygotowana dokumentacja pozwala ocenić skuteczność działań i usprawnić procedury na przyszłość.
-
Ustalanie priorytetów w procesie przywracania operacji
Kolejność przywracania usług powinna być oparta na jasno określonych kryteriach:
- klasyfikacja zasobów pod kątem ich krytyczności,
- znaczenie usług dla funkcjonowania organizacji,
- zależności między usługami – priorytet powinny mieć te usługi, które są niezbędne dla innych procesów.
-
Planowanie zasobów i pojemności
Należy zadbać o odpowiednią wydajność systemów przetwarzania informacji, łączności i wsparcia środowiskowego po aktywacji planu. Kluczowe są:
- zapewnienie zdolności operacyjnej systemów podstawowych i rezerwowych,
- współpraca z alternatywnymi dostawcami usług telekomunikacyjnych.
-
Przygotowanie do odtworzenia usług
Proces przywracania usług po awarii wymaga konkretnych działań, takich jak:
- tworzenie zapasowych lokalizacji (failover sites),
- zabezpieczanie kopii zapasowych danych o najwyższym priorytecie w lokalizacjach zdalnych.
-
Współpraca z dostawcami zewnętrznymi
Usługi świadczone przez podmioty trzecie muszą być dostępne w sytuacji awaryjnej, np. przez gotowe środowiska zapasowe (hot sites).
-
Wdrożenie zaawansowanych mechanizmów odzyskiwania
Aby zwiększyć skuteczność działań naprawczych, warto zastosować:
- pełną redundancję kluczowych zasobów,
- mechanizmy przełączania awaryjnego (failover),
- alternatywne lokalizacje operacyjne.

Przykłady dowodów skutecznej realizacji planu ciągłości działania i planu odzyskiwania po awarii
Wdrożenie planu ciągłości działania i planu odzyskiwania po awarii powinno być poparte konkretnymi czynnościami oraz dowodami na ich skuteczność. Wytyczne ENISA wskazują, jakie elementy mogą świadczyć o odpowiednim przygotowaniu organizacji.
-
Środki zaradcze na wypadek katastrof
Organizacja powinna mieć wdrożone mechanizmy umożliwiające szybkie przywrócenie usług, takie jak:
- lokalizacje zapasowe (failover sites) w innych regionach,
- kopie zapasowe danych przechowywane w lokalizacjach zdalnych,
- inne środki zapewniające redundancję krytycznych zasobów.
-
Aktualne struktury organizacyjne
Struktura organizacyjna powinna być:
- aktualna,
- jasno zdefiniowana,
- szeroko zakomunikowana w organizacji, aby wszyscy pracownicy wiedzieli, jakie są ich role i obowiązki w sytuacjach kryzysowych.
-
Mapowanie zależności między sektorami i usługami
Niezbędne jest opracowanie:
- mapy sektorów oraz usług krytycznych dla organizacji,
- planów awaryjnych, które minimalizują wpływ zakłóceń na sektory zależne oraz współzależne,
- strategii zarządzania ryzykiem wynikającym z przerw w działaniu sieci lub usług.
Analiza wpływu zakłóceń i cele odzyskiwania
Zgodnie z wumogami NIS2 organizacje powinny przeprowadzić analizę wpływu zakłóceń na działalność (Business Impact Analysis – BIA), aby ocenić potencjalne skutki poważnych przerw w funkcjonowaniu systemów. Na podstawie wyników BIA oraz analizy ryzyka należy określić kluczowe cele odzyskiwania i wdrożyć odpowiednie procedury zapewniające ciągłość działania.
-
Kluczowe cele odzyskiwania (RTO, RPO, SDO)
- Recovery Time Objective (RTO) – maksymalny dopuszczalny czas na przywrócenie zasobów i funkcji biznesowych (np. systemów ICT) po wystąpieniu awarii.
- Recovery Point Objective (RPO) – dopuszczalna ilość utraconych danych w wyniku przerwy w działaniu konkretnych systemów lub aplikacji.
- Service Delivery Objective (SDO) – minimalny poziom wydajności, który musi zostać osiągnięty przez procesy biznesowe podczas działania w trybie awaryjnym.
Wartości RTO, RPO i SDO pozwalają określić priorytety oraz zdefiniować procedury tworzenia kopii zapasowych i redundancji systemów.
-
Dokumentowanie planu odzyskiwania po awarii
Skuteczny plan odzyskiwania powinien uwzględniać:
- zdefiniowane cele RTO, RPO i SDO,
- zgodność z obowiązującymi przepisami i regulacjami prawnymi.
-
Przykłady dowodów na zgodność z wymaganiami
- Udokumentowana analiza BIA wraz z określonymi celami odzyskiwania.
- Procesy, procedury i środki zapewniające wymagany poziom ciągłości działania w sytuacjach kryzysowych.

Testowanie i aktualizowanie planu ciągłości działania i planu odzyskiwania po awarii
Wytyczne ENISA jednoznacznie podkreślają, że plan ciągłości działania (BCP) oraz plan odzyskiwania po awarii (DRP) muszą być regularnie testowane, przeglądane i aktualizowane. Celem tych działań jest nie tylko weryfikacja ich skuteczności, lecz także uwzględnienie wniosków z przeszłych testów oraz ze znaczących zmian w działalności organizacji.
-
Regularne testowanie i przegląd planów
Plany powinny być testowane co najmniej raz w roku oraz:
- po wystąpieniu istotnych incydentów,
- po zmianach w infrastrukturze lub ryzykach.
Przy testach należy uwzględnić:
- dzienniki zmian (change logs),
- wcześniejsze incydenty,
- wyniki poprzednich testów.
-
Testowanie alternatywnych lokalizacji przetwarzania
W ramach testów planów odzyskiwania po awarii należy:
- zapoznać personel z funkcjonowaniem obiektów i z zasobami,
- ocenić zdolność alternatywnego środowiska do utrzymania operacji.
-
Testowanie infrastruktury centrum danych
Testy powinny obejmować:
- dostępność zasobów,
- mechanizmy automatycznego przełączania awaryjnego (auto failover),
- odporność infrastruktury na zakłócenia i zdolność do zapewnienia ciągłości usług.
-

Bezpłatna wiedza o RODO.
Korzystaj do woli!Webinary, artykuły, poradniki, szkolenia, migawki i pomoc. Witaj w bazie wiedzy ODO 24.WCHODZĘ W TOPełne odtworzenie systemów
Celem testów powinno być przywrócenie systemu do znanego stanu. Pozwala to potwierdzić skuteczność procedur odzyskiwania.
-
Aktualizacja planów i działań
Na podstawie testów należy regularnie aktualizować:
- dzienniki zmian,
- wyniki testów operacyjnych,
- dokumentację wyników szkoleń i działań testowych.
-
Przegląd ról i odpowiedzialności
Należy okresowo weryfikować i aktualizować role oraz obowiązki personelu odpowiedzialnego za realizację planów ciągłości działania.
-
Zarządzanie dostawcami zewnętrznymi
Weryfikacja planów odzyskiwania po awarii podmiotów trzecich jest kluczowa dla zapewnienia zgodności z wymaganiami organizacji.
-
Komunikacja zmian
Każda aktualizacja planów ciągłości działania (BCP) i planów odzyskiwania po awarii (DRP) powinna być skutecznie zakomunikowana kluczowym członkom zespołów odpowiedzialnych za ich realizację.
Przykłady dowodów na skuteczne testowanie i aktualizowanie planu ciągłości działania i planu odzyskiwania po awarii
Wdrażanie i utrzymywanie planu ciągłości działania (BCP) oraz planu odzyskiwania po awarii (DRP) wymaga przeprowadzania regularnych testów i dokumentowania ich wyników. Wytyczne ENISA wskazują podstawowe przykłady dowodów potwierdzających skuteczność tych działań.
-
Udokumentowane plany i harmonogramy testów
Organizacja powinna posiadać:
- harmonogramy przyszłych testów,
- plany regularnego przeglądu oraz aktualizacji.
-
Rejestry z wcześniejszych testów i przeglądów
Dowody na przeprowadzenie testów i przeglądów obejmują:
- wyniki wcześniejszych testów,
- zapisy z przeglądów i wprowadzone aktualizacje na podstawie wniosków z testów.
-
Dzienniki realizacji planów BCP i DRP
Dzienniki realizacji planów ciągłości działania (BCP) i planów odzyskiwania po awarii (DRP) powinny zawierać szczegółowe informacje dotyczące:
- podjętych decyzji,
- wykonanych kroków w procesie,
- ostatecznego czasu przywrócenia działania.
-
Komunikacja zmian
Należy gromadzić dowody potwierdzające komunikację dotyczącą zmian w planach, takie jak:
- e-maile,
- dokumenty,
- ogłoszenia w intranecie.
-
Aktualizacje planów i procedur
Dowody wprowadzonych zmian obejmują:
- zaktualizowane plany, procedury oraz zmiany w przepływach pracy (workflow),
- uwzględnienie wniosków wyciągniętych z poprzednich testów w bieżących planach.
Zarządzanie kopiami bezpieczeństwa
Odpowiednie zarządzanie kopiami zapasowymi (backup management) jest fundamentem utrzymania ciągłości działania i odporności organizacji na zakłócenia. Zgodnie z ustawą o KSC organizacje muszą utrzymywać kopie zapasowe danych oraz zapewniać odpowiednie zasoby – zarówno techniczne, jak i ludzkie – aby osiągnąć wymagany poziom redundancji.
Wytyczne dotyczące zarządzania kopiami zapasowymi
Organizacje powinny:
- określić strategię redundancji – zdecydować, czy inwestować we własne rozwiązania backupowe, czy skorzystać z usług podmiotów zewnętrznych, takich jak dostawcy usług chmurowych,
- zapewnić fizyczną separację kopii zapasowych – aby zminimalizować ryzyko utraty danych w przypadku awarii lokalnej.

OFERTA PROMOCYJNA
Czas na skuteczne wdrożenie wymogów NIS2 określonych w ustawie o KSC
Zastanawiasz się, jak kompleksowo przygotować firmę do nowej dyrektywy? Podczas krótkiej rozmowy, poznasz ofertę i otrzymasz rabat
Przykłady dowodów skutecznego zarządzania backupami
- Kopie zapasowe są fizycznie oddzielone od głównych systemów przetwarzania danych.
- W przypadku usług świadczonych przez podmioty trzecie organizacja posiada umowy SLA (Service Level Agreements), które określają poziom usług, wymagania dotyczące dostępności oraz czas odzyskiwania danych.
Planowanie zarządzania kopiami zapasowymi
Na podstawie wyników analizy ryzyka i planu ciągłości działania organizacje muszą opracować szczegółowe plany zarządzania kopiami zapasowymi. Celem jest zapewnienie bezpieczeństwa danych, ich dostępności i zgodności z wymogami prawnymi oraz operacyjnymi.
Elementy skutecznego planu zarządzania kopiami zapasowymi
-
Czas odzyskiwania danych
Określenie maksymalnych czasów przywracania danych i systemów zgodnie z wyznaczonymi celami odzyskiwania (RTO).
-
Integralność i dokładność kopii zapasowych
Zapewnienie kompletności i poprawności kopii zapasowych, włącznie z danymi konfiguracyjnymi i ze środowiskami przechowywanymi w chmurze.
-
Bezpieczne przechowywanie kopii
Kopie zapasowe powinny być przechowywane:
- offline lub online w lokalizacjach poza główną siecią,
- w bezpiecznej odległości, aby uniknąć zniszczeń w przypadku katastrofy w lokalizacji głównej.
-
Środki kontroli dostępu
Wdrożenie fizycznych i logicznych zabezpieczeń adekwatnych do klasyfikacji zasobów w celu ochrony kopii przed nieuprawnionym dostępem.
-
Przywracanie danych
Opracowanie procedur przywracania danych z kopii zapasowych, aby zagwarantować szybki i skuteczny proces odzyskiwania.
-
Okresy przechowywania danych
Uwzględnienie wymogów biznesowych oraz przepisów prawnych w zakresie retencji danych.
Przykłady dowodów skutecznego zarządzania kopiami zapasowymi
- Plany backupowe – szczegółowa dokumentacja harmonogramów i procedur wykonywania kopii zapasowych.
- Logi z oprogramowania backupowego – potwierdzające regularne tworzenie kopii.
- Fizyczna separacja kopii zapasowych – przechowywanie kopii poza główną lokalizacją i ich zabezpieczenie (np. zaszyfrowanie).
- Raporty potwierdzające kopię offsite – np. w chmurze lub zdalnym centrum danych.
- Konfiguracja oprogramowania backupowego – weryfikacja, czy dane są kopiowane i przechowywane na różnych nośnikach.
- Procedury przywracania danych – jasne i precyzyjne instrukcje obejmujące wszystkie kluczowe systemy i usługi.
- Ustawienia usług chmurowych – potwierdzenie konfiguracji do odbierania i przechowywania kopii zapasowych.

Praca dobrymi narzędziami RODO to nie praca!
Weryfikacja integralności kopii zapasowych
Regularna kontrola integralności kopii zapasowych jest niezbędna, aby zapewnić ich niezawodność i gotowość do przywrócenia danych w sytuacjach kryzysowych. Dyrektywa NIS2 wskazuje najlepsze praktyki, które organizacje powinny wdrożyć w celu zapewnienia skutecznej ochrony danych.
Dobre praktyki w zakresie weryfikacji integralności kopii zapasowych
-
Algorytmy sum kontrolnych (checksums) i funkcje skrótu (hashing)
Używanie sum kontrolnych lub algorytmów hashowania do weryfikacji, czy dane w kopiach zapasowych są zgodne z oryginałem.
-
Automatyzacja testów integralności
Wdrożenie skryptów automatycznie uruchamiających testy integralności, aby zminimalizować ryzyko błędów ludzkich.
-
Regularne testy przywracania danych
Planowanie i przeprowadzanie regularnych testów, które polegają na przywracaniu danych z kopii zapasowych w celu sprawdzenia ich kompletności i funkcjonalności.
-
Scenariusze odzyskiwania
Testowanie różnych scenariuszy odzyskiwania, w tym pełnych przywróceń systemu oraz odzyskiwania poszczególnych plików, aby mieć pewność, że systemy backupowe działają zgodnie z oczekiwaniami.
-
Rozwiązania chmurowe
Rozważenie użycia rozwiązań chmurowych do kopii zapasowych poza lokalizacją (offsite), które często oferują wbudowane mechanizmy weryfikacji integralności i redundancji danych.
Przykłady dowodów potwierdzających skuteczną weryfikację kopii zapasowych
- Logi lub raporty potwierdzające użycie sum kontrolnych (checksums) lub algorytmów hashowania.
- Ustawienia w oprogramowaniu backupowym lub skrypty określające zastosowanie metod weryfikacji integralności danych.
- Rejestry z regularnych testów przywracania danych z kopii zapasowych.
- Dowody testów różnych scenariuszy odzyskiwania danych, takich jak pełne przywrócenie systemu lub odzyskiwanie pojedynczych plików.
- Logi z incydentów, w których wdrożono procedury odzyskiwania danych i które zakończyły się sukcesem.
- W przypadku korzystania z usług podmiotów trzecich – umowy SLA (Service Level Agreement) określające wymagania dotyczące integralności kopii zapasowych.
Zapewnienie dostępności zasobów i redundancji
Na podstawie wyników analizy ryzyka i planu ciągłości działania organizacje muszą zapewnić dostępność zasobów przez wdrożenie co najmniej częściowej redundancji. Dotyczy to systemów, zasobów, personelu oraz kanałów komunikacji.
Obszary wymagające redundancji
-
Systemy sieciowe i informacyjne
Organizacja powinna zapewnić redundancję systemów dzięki takim rozwiązaniom, jak:
- korzystanie z wielu dostawców usług internetowych,
- równoważenie obciążenia (load balancing),
- serwery lustrzane (mirrored servers),
- wirtualizacja zasobów,
- macierze dyskowe RAID (Redundant Array of Independent Disks).
-
Zasoby i infrastruktura
Redundancja powinna obejmować:
- współdzielone przestrzenie robocze,
- lokalizacje zapasowe dla danych i systemów,
- sprzęt rezerwowy,
- wielu dostawców dla tych samych kategorii produktów w celu ograniczenia ryzyka przerw w dostawach.
-
Personel i kompetencje
Personel powinien być przygotowany do zapewnienia ciągłości działania. Można to zrobić dzięki:
- rotacji stanowisk (job rotation),
- przypisaniu zadań backupowych,
- przeprowadzeniu ćwiczeń awaryjnych (emergency drills).
-
Kanały komunikacyjne
Niezbędne jest zapewnienie dostępu do wielu platform komunikacyjnych, takich jak:
- media społecznościowe,
- aplikacje do komunikacji,
- e-mail oraz inne kanały zapewniające ciągłość komunikacji.
Przykłady dowodów na wdrożenie redundancji
- Potwierdzenie wdrożenia jednego lub więcej z wymienionych mechanizmów.
- Dokumentacja wskazująca na działające systemy redundancji i ich testowanie (np. logi, raporty z testów).

Monitorowanie i dostosowanie zasobów w kontekście redundancji
Organizacje powinny zapewnić skuteczne monitorowanie oraz dostosowanie zasobów (w tym systemów, infrastruktury i personelu), uwzględniając wymagania dotyczące redundancji i kopii zapasowych. Kluczowymi etapami tego procesu są priorytetyzacja i stała weryfikacja dostępnych zasobów.
Wytyczne dotyczące zarządzania zasobami
-
Priorytetyzacja zasobów
Oparcie alokacji zasobów na wynikach analizy ryzyka, aby zapewnić ich odpowiednie wykorzystanie w sytuacjach kryzysowych.
-
Częściowa redundancja
Wprowadzenie redundancji w tych obszarach, gdzie jest to najbardziej istotne dla utrzymania krytycznych funkcji organizacji.
-
Różnorodne lokalizacje backupowe
Rozmieszczenie kopii zapasowych w różnych lokalizacjach, aby zminimalizować ryzyko utraty danych w przypadku awarii lub katastrof lokalnych.
-
Ciągłe monitorowanie zasobów
Przeprowadzanie regularnej kontroli zasobów w celu identyfikacji obszarów wymagających dodatkowej redundancji lub dostosowania alokacji.
Przykłady dowodów potwierdzających zgodność
- Dokumentacja potwierdzająca wdrożenie elementów wskazanych w ramach redundancji i monitorowania.
- Dowody z przeprowadzonych symulacji oraz działań podnoszących świadomość personelu, które oceniają gotowość organizacji oraz skuteczność wdrożonych procedur.
Regularne testowanie odzyskiwania kopii zapasowych i redundancji
Organizacje są zobowiązane do przeprowadzania regularnych testów odzyskiwania kopii zapasowych i mechanizmów redundancji, aby upewnić się, że w sytuacjach kryzysowych można na tych kopiach polegać. Testy muszą obejmować nie tylko dane, lecz także procedury i wiedzę niezbędne do skutecznego przywrócenia operacji. Wyniki testów powinny być dokumentowane, a wszelkie problemy – korygowane na bieżąco.
Wytyczne dotyczące testowania kopii zapasowych
-
Dostosowanie częstotliwości testów do krytyczności danych
Częstotliwość testowania danych powinna być dostosowana do ich krytyczności:
-
dane o wysokim priorytecie powinny być testowane co tydzień,

Migracje, chmury, systemy.
RODO w IT.Szkolenie RODO w IT dla inspektorów ochrony danych oraz managerów i pracowników IT. Zapraszamy!SPRAWDŹ TERMINY - dane o średnim i niskim priorytecie mogą być sprawdzane co miesiąc,
- istotne zmiany w danych lub systemach należy testować natychmiast po ich wprowadzeniu.
-
Analiza i aktualizacja procedur
Wnioski z testów powinny być przetwarzane przez odpowiedzialne osoby, a procesy i systemy – regularnie aktualizowane.
-
Współpraca z dostawcami i partnerami
Należy angażować zewnętrznych dostawców, partnerów biznesowych oraz klientów w testowanie scenariuszy przywracania, aby upewnić się, że wszystkie zależne elementy działają prawidłowo.
Przykłady dowodów skutecznego testowania
- Regularne testy statusu kopii zapasowych oraz procedur odzyskiwania.
- Program testów backupu, uwzględniający scenariusze awaryjne, częstotliwość testów, role i procedury.
- Raporty z testów i symulacji, w tym lekcje wyciągnięte z przeprowadzonych działań.
- Dokumentacja dowodząca realizacji przeszłych testów i podjętych działań naprawczych.
- Zaktualizowane plany testowe, uwagi z przeglądów oraz logi zmian.
- Informacje zwrotne od dostawców oraz podmiotów zewnętrznych dotyczące usprawnień scenariuszy testowych.
Zarządzanie kryzysowe
Organizacje muszą wdrożyć proces zarządzania kryzysowego, który pozwoli skutecznie reagować na incydenty o znacznym wpływie na zasoby, operacje lub reputację. Dyrektywa NIS2 podkreśla konieczność zdefiniowania jasnych kryteriów eskalacji incydentów do poziomu kryzysowego oraz określenia progów tolerancji ryzyka.
Kryteria identyfikacji sytuacji kryzysowej
Kryzys może zostać ogłoszony w przypadku:
- incydentów stanowiących poważne ryzyko dla kluczowych zasobów i operacji – są to ataki o wysokiej krytyczności, takie jak wycieki danych zawierających informacje wrażliwe,
- incydentów zakłócających znacząco działalność operacyjną organizacji – powodujących przedłużone przestoje, utratę dostępu do usług czy negatywny wpływ na obsługę klienta,
- incydentów mających szeroki zasięg oddziaływania – obejmujących wiele systemów, działów lub lokalizacji, co wskazuje na poważniejsze zagrożenie,
- incydentów negatywnie wpływających na reputację organizacji – które mogą prowadzić do publicznej krytyki lub utraty zaufania klientów, dlatego wymagają natychmiastowej eskalacji,
- incydentów wiążących się z zaawansowanymi zagrożeniami – ataki takie jak zaawansowane trwałe zagrożenia (APT) lub działania zorganizowanej cyberprzestępczości mogą wymagać odpowiedzi wykraczającej poza standardowe procedury,
- incydentów mogących eskalować – kryzys może się pogłębiać, np. gdy istnieją luki umożliwiające ponowny atak lub gdy rozprzestrzenia się oprogramowanie złośliwe.
Przykład dowodu skutecznego zarządzania kryzysowego
- Proces zarządzania kryzysowego jest zgodny z udokumentowanymi standardami oraz najlepszymi praktykami.
Elementy skutecznego zarządzania kryzysowego
Organizacje muszą wdrożyć taki proces zarządzania kryzysowego, który będzie obejmować elementy pozwalające skutecznie reagować na sytuacje awaryjne oraz utrzymać bezpieczeństwo sieci i systemów informacyjnych.

Podstawowe elementy procesu zarządzania kryzysowego
-
Role i odpowiedzialności
- Wyznaczenie konkretnych ról dla pracowników, dostawców oraz innych podmiotów zaangażowanych w działania kryzysowe.
- Opracowanie szczegółowych kroków postępowania dla każdej z ról w sytuacji kryzysowej.
-
Komunikacja
- Zapewnienie skutecznych środków komunikacji między organizacją a odpowiednimi organami nadzorczymi.
- Ustalanie zarówno obowiązkowych komunikatów (np. raporty z incydentów, harmonogram działań), jak i nieobligatoryjnych sposobów komunikacji.
-
Bezpieczeństwo sieci i systemów
- Wdrażanie odpowiednich środków, które pozwolą utrzymać bezpieczeństwo i funkcjonalność systemów IT podczas sytuacji kryzysowych.
Wytyczne dotyczące komunikacji w sytuacjach kryzysowych
Skuteczny proces komunikacji w sytuacjach kryzysowych powinien obejmować:
- sposoby przekazywania informacji interesariuszom – określenie, jak informacje będą dystrybuowane do kluczowych osób i organizacji,
- szablony komunikacyjne – gotowe wzory wiadomości i raportów kryzysowych,
- aktualne dane kontaktowe – dla interesariuszy wewnętrznych (pracowników) i zewnętrznych (klientów, dostawców, organów nadzorczych, służb ratunkowych).
Zarządzanie informacjami o incydentach, zagrożeniach i środkach zaradczych
Organizacje są zobowiązane do wdrożenia procesu zarządzania informacjami otrzymywanymi od zespołów reagowania na incydenty bezpieczeństwa (CSIRT) lub od właściwych organów nadzorczych. Informacje te mogą dotyczyć incydentów, podatności, zagrożeń oraz potencjalnych środków zaradczych.
Kluczowe kroki w procesie zarządzania informacjami
-
Wyznaczenie punktu kontaktowego
Organizacja powinna wskazać punkt kontaktowy odpowiedzialny za współpracę z CSIRT-ami. Musi on zapewniać ekspertów posiadających odpowiednią wiedzę z zakresu incydentów i analiz zagrożeń.
-
Klasyfikacja informacji
Otrzymane informacje należy klasyfikować według kategorii, takich jak:

- incydenty,
- podatności,
- zagrożenia,
- środki zaradcze.
-
Priorytetyzacja informacji
Poziomy priorytetu należy przypisać adekwatnie do ważności zagrożenia oraz jego potencjalnego wpływu na organizację.
-
Weryfikacja informacji
Celem przekazania informacji do CSIRT-ów lub zespołów kontaktowych jest ich weryfikacja pod kątem:
- trafności,
- pilności,
- zgodności z istniejącymi logami, źródłami analitycznymi i politykami bezpieczeństwa.
-
Opracowanie strategii zaradczej
W przypadku podatności i zagrożeń organizacja powinna współpracować z odpowiednimi zespołami (IT, bezpieczeństwo, operacje) w celu opracowania i wdrożenia strategii minimalizacji ryzyka.
-
Aktualizacja planów reagowania na incydenty
Plany reagowania powinny być aktualizowane lub tworzone na nowo w zależności od charakteru i skali zagrożenia.
-
Komunikacja i wdrażanie środków zaradczych
Środki zaradcze powinny być wdrożone, a informacje – przekazywane do odpowiednich interesariuszy oraz organów nadzorczych zgodnie z wymaganiami regulacyjnymi.
-
Dzielenie się wiedzą
Organizacje powinny dzielić się wnioskami oraz informacjami o incydentach z CSIRT-ami, aby wspierać szerszą społeczność cyberbezpieczeństwa.
Przykład dowodu zgodności z procesem zarządzania informacjami
- Dokumentacja z wcześniejszej komunikacji, np. e-maile, korespondencja, protokoły spotkań z CSIRT-ami lub właściwymi organami nadzorczymi.
Testowanie i aktualizowanie planu zarządzania kryzysowego
Organizacje muszą regularnie testować, przeglądać i aktualizować plan zarządzania kryzysowego. Dzięki temu mogą zapewnić jego skuteczność i dostosowanie do zmieniających się zagrożeń oraz operacji. Testy powinny odbywać się cyklicznie oraz po wystąpieniu znaczących incydentów lub zmian operacyjnych.
Wytyczne dotyczące testowania planu zarządzania kryzysowego
-
Zakres i częstotliwość testów
Plan zarządzania kryzysowego powinien być regularnie poddawany:
- pełnym testom – przeprowadzanym co najmniej dwa razy w roku,
- testom wytrzymałościowym i komponentowym – realizowanym raz w roku, aby ocenić konkretne elementy planu zarządzania kryzysowego.
-
Sposób testowania
Proces testowania powinien obejmować:
- analizę wcześniejszych kryzysów i sytuacji awaryjnych,
- porównanie wyników testów z wcześniej ustalonymi celami odzyskiwania (np. RTO, RPO i SDO),
- identyfikację obszarów wymagających usprawnień i aktualizację procedur zarządzania kryzysowego.
-
Aktualizacja planu
Po zakończeniu testów lub po wystąpieniu znaczących zmian organizacyjnych i operacyjnych należy:
- zaktualizować procedury zarządzania kryzysowego,
- dokonać przeglądu polityk bezpieczeństwa sieci i systemów informacyjnych.
Przykłady dowodów na skuteczne testowanie i aktualizowanie planu zarządzania kryzysowego
- Dokumentacja pokazująca integrację zarządzania kryzysowego z planami reagowania na incydenty.
- Zidentyfikowane wcześniejsze kryzysy oraz analiza ich wpływu na operacje biznesowe.
- Raporty z testów planu zarządzania kryzysowego, zawierające szczegóły dotyczące scenariuszy testowych, listę zaangażowanych uczestników oraz wyniki.
- Raporty ewaluacyjne po testach, wskazujące mocne strony, słabości oraz obszary wymagające usprawnień.
- Rejestry przeglądów wewnętrznych i zewnętrznych oraz audytów planu, wraz z wnioskami i podjętymi działaniami naprawczymi.
Sprawdź co pamiętasz - za poprawną odpowiedź nagroda!
Który z poniższych elementów nie jest kluczowym składnikiem planu ciągłości działania (BCP) i planu odzyskiwania po awarii (DRP) zgodnie z wytycznymi NIS2?
Od czego zacząć wdrożenie wymogów NIS2 określonych w ustawie o KSC?
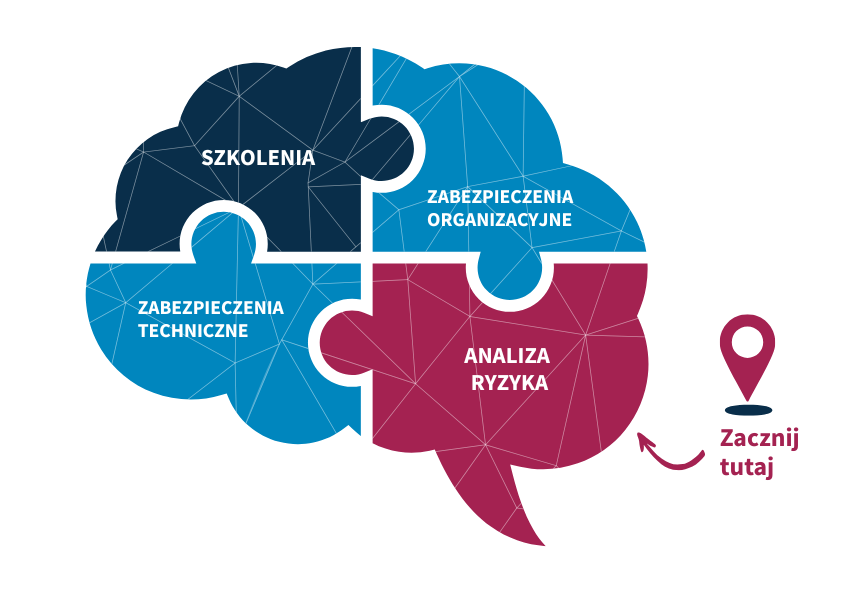
Wdrożenie wymogów NIS2 określonych w ustawie o KSC należy rozpocząć od analizy ryzyka – to pierwszy i kluczowy krok, który pozwala zidentyfikować zasoby, zagrożenia oraz luki w zabezpieczeniach.
Dlaczego to takie ważne?
NIS2, podobnie jak RODO, nie precyzuje konkretnych środków ochrony – to Ty, na podstawie przeprowadzonej analizy ryzyka, musisz określić adekwatne środki zabezpieczeń.
Kolejne kroki wdrożenia KSC / NIS2 to:
1. Zabezpieczenia techniczne
Inwestycje w konkretne technologie i narzędzia ochronne. NIS2 wymaga realnego, „twardego" bezpieczeństwa, a nie tylko dokumentacji.
2. Zabezpieczenia organizacyjne
Opracowanie i wdrożenie procedur wymaganych przez KSC / NIS2. Dzięki nim pracownicy będą wiedzieli, jak bezpiecznie działać w ramach infrastruktury IT.
3. Szkolenia
Regularna edukacja pracowników i zarządu, która zapewni świadomość ról, obowiązków i zasad bezpieczeństwa. To bezpośredni wymóg NIS2.
Podsumowując: zacznij od analizy ryzyka, a dopiero potem zadbaj o odpowiednie zabezpieczenia techniczne, organizacyjne i szkolenia.