


Pseudonimizacja – czym jest, jakie są jej cele i kiedy jest efektywna?

Odbierz pakiet bezpłatnych poradników i mikroszkoleń RODO
Ponieważ pseudonimizacja może być odwracalna, należy odróżnić od niej anonimizację, tzn. proces zmiany danych osobowych w taki sposób, że osoba fizyczna nie może być już ani bezpośrednio, ani pośrednio zidentyfikowana zarówno przez administratora, jak i we współpracy z jakąkolwiek stroną trzecią.
Najbardziej typowe cele pseudonimizacji to:
- ukrycie prawdziwej tożsamości osoby, której dane dotyczą,
- ograniczenie możliwości powiązania danych z różnych domen,
- minimalizacja danych i ograniczenie dostępu osobom, którym do pracy wystarczy dostęp do pseudonimów,
- zapewnienie prawidłowości danych (np. kody kreskowe i kody QR).
Efektywność pseudonimizacji mającej na celu zabezpieczenie danych ocenia się według następujących kryteriów:
- D1 – pseudonimy nie powinny pozwalać na łatwe odwrócenie pseudonimizacji przez jakąkolwiek stronę trzecią (jakiegokolwiek innego administratora danych osobowych lub procesora) w ramach danego kontekstu przetwarzania (tak, aby ukryć pierwotne identyfikatory w konkretnym kontekście),
- D2 – jakakolwiek strona trzecia nie powinna mieć możliwości reprodukcji pseudonimów w trywialny sposób (aby uniknąć wykorzystania takich samych pseudonimów w różnych domenach).
Poza skutecznością zabezpieczenia efektywność oznacza także, że pseudonimizacja nie utrudnia pracy. Kluczowym pojęciem jest tutaj skalowalność, tzn. zapewnienie możliwości sprawnego działania i odwrócenia pseudonimizacji nawet w przypadku dużej bazy danych.
Metody pseudonimizacji
W wytycznych w zakresie kształtowania technologii w zgodzie z przepisami RODO – przegląd dotyczący pseudonimizacji danych zawarto następujące schematy przedstawiające różne warianty pseudonimizacji – od najprostszych do najbardziej skomplikowanych
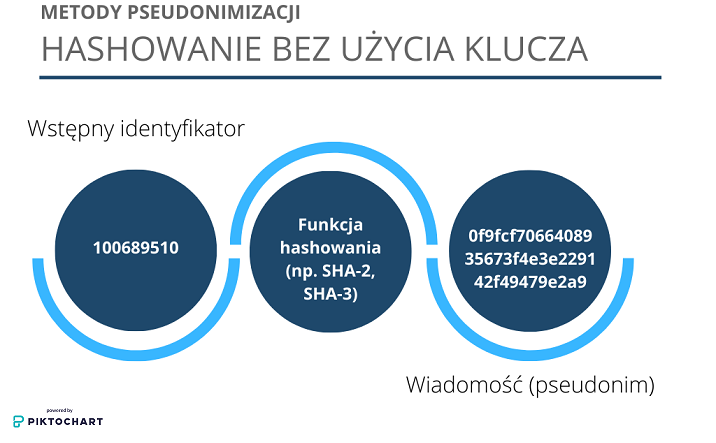
Hashowanie bez użycia klucza (np. metodą SHA-2, SHA-3) – są to ogólnodostępne metody, dzięki którym dowolny identyfikator (poniżej: wstępny identyfikator – initial identifier) można zamienić na bardziej skomplikowany ciąg, niezrozumiały dla osoby nieznającej funkcji, którą zastosowano. Metoda ta najczęściej nie spełnia wyżej wymienionych celów D1 i D2, w związku z czym bardziej nadaje się jako sposób zapewnienia prawidłowości danych niż jako skuteczne zabezpieczenie.
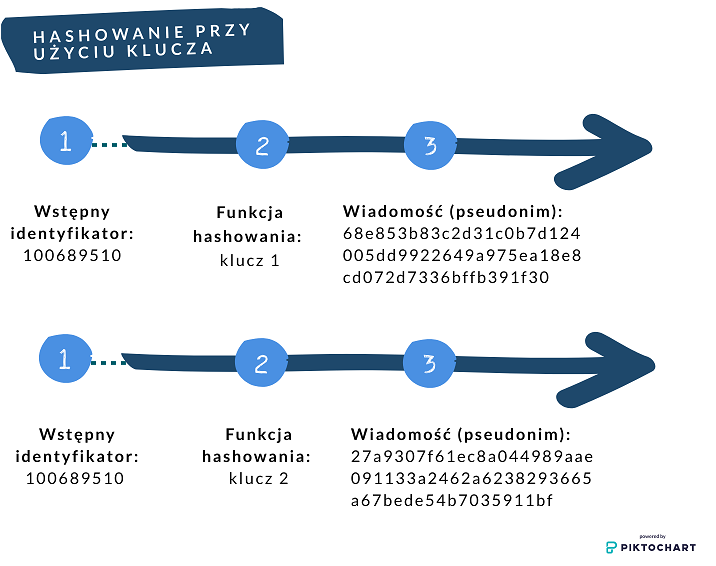
Hashowanie przy użyciu klucza (w zależności od poziomu bezpieczeństwa – tajnego lub publicznego) – w tym przypadku treść pseudonimu zależy nie tylko od funkcji, lecz także od treści wprowadzonego klucza. Zastosowanie różnych kluczy daje różne pseudonimy dla tego samego identyfikatora.
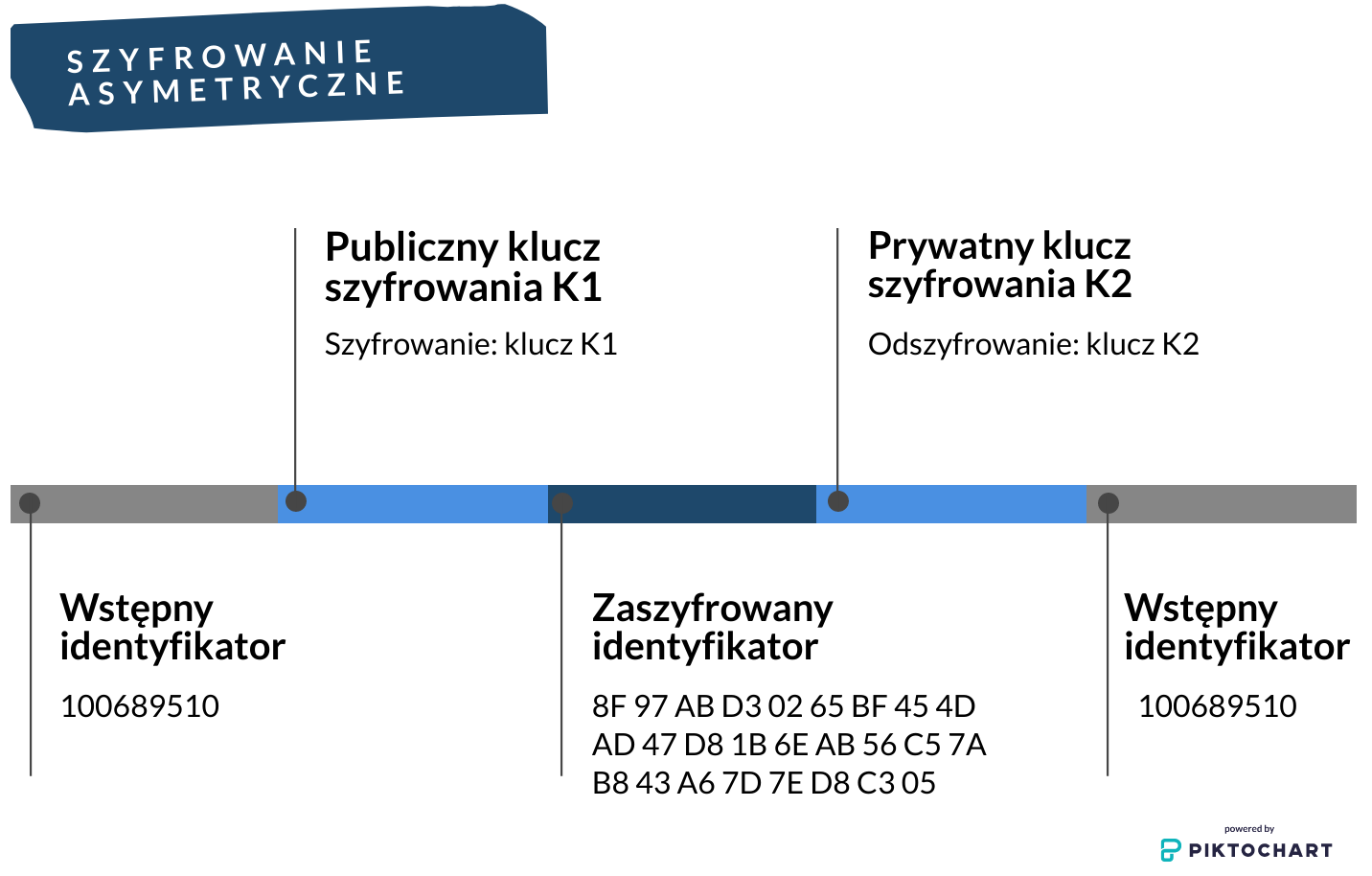
Szyfrowanie asymetryczne – zamiast jednego klucza można stosować np. publiczny klucz szyfrowania, znany jednostce upoważnionej do dokonania pseudonimizacji, oraz klucz odszyfrowania, znany wyłącznie jednostce upoważnionej do odwrócenia pseudonimizacji.
Pseudonimizacja – czym jest, jakie są jej cele i kiedy jest efektywna?
W wytycznych w zakresie technik i najlepszych praktyk pseudonimizacji zawarto następujące scenariusze, przedstawiające, w jaki sposób można ograniczyć dostęp do danych poszczególnych podmiotów:
Scenariusz I:
pseudonimizacja na potrzeby wewnętrzne. Dane osób fizycznych (data subjects) są pseudonimizowane przez administratora (data controller), który zna sekret pseudonimizacji, tzn. wie, w jaki sposób ją odwrócić. Ten rodzaj zabezpieczenia pozwala np. zdecydować, że część pracowników będzie pracować jedynie na danych spseudonimizowanych w przypadku, gdy nie musi znać tożsamości osób, których dane przetwarza.
Przykład:
Osoby, których dane dotyczą: Alicja, Tomasz, Jakub.
Administrator dokonuje pseudonimizacji: Alice -> 15, Bob -> 28,Charly -> 3
Scenariusz II:
podmiot przetwarzający (processor) gromadzi dane, a administrator dokonuje pseudonimizacji.
Przykład:
Osoby, których dane dotyczą: Alicja, Tomasz, Jakub.
Podmiot przetwarzający: Alicja, Tomasz, Jakub.
Administrator dokonuje pseudonimizacji: Alice -> 15, Bob -> 28,Charly -> 3
Scenariusz III:
powierzenie podmiotowi przetwarzającemu spseudonimizowanych danych (inny wariant: przesłanie spseudonimizowanych danych innemu administratorowi).
Przykład:
Osoby, których dane dotyczą: Alicja, Tomasz, Jakub.
Administrator dokonuje pseudonimizacji: Alice -> 15, Bob -> 28,Charly -> 3
Podmiot przetwarzający otrzymuje spseudonimizowane dane: 15, 28, 3
Scenariusz IV:
podmiot przetwarzający zbiera dane i dokonuje pseudonimizacji, działając na polecenie administratora (administrator nie zna tożsamości osób, których dane otrzymuje, co zwiększa jego poziom bezpieczeństwa). Wariantem jest łańcuch procesorów dokonujących pseudonimizacji.
Przykład:
Osoby, których dane dotyczą: Alicja, Tomasz, Jakub.
Podmiot przetwarzający dokonuje pseudonimizacji: Alice -> 15, Bob -> 28,Charly -> 3
Administrator otrzymuje spseudonimizowane dane: 15, 28, 3
Scenariusz V:
pseudonimizacji dokonuje trzecia strona (nie procesor). Przykładem zastosowania tego scenariusza jest współadministrowanie – wówczas wystarczy, aby jeden ze współadministratorów (będący w roli zaufanej trzeciej strony – TTP) znał tożsamość osób fizycznych.
Przykład:
Osoby, których dane dotyczą: Alicja, Tomasz, Jakub.
Zaufana trzecia strona (TTP) dokonuje pseudonimizacji: Alice -> 15, Bob -> 28,Charly -> 3
Administrator otrzymuje spseudonimizowane dane: 15, 28, 3
Scenariusz VI:
pseudonimizacji dokonuje sama osoba, której dane dotyczą. Przykład: para kluczy w ramach kryptowalut oraz wszystkie inne przypadki, gdy administrator nie musi znać prawdziwej tożsamości osoby, której dane dotyczą..
Przykład:
Osoby, których dane dotyczą, dokonują pseudonimizacji: Alice -> 15, Bob -> 28,Charly -> 3
Administrator otrzymuje spseudonimizowane dane: 15, 28, 3
Ataki na pseudonimizację

Funkcja IOD.
To się dobrze przekazuje
- wewnętrzny – przeciwnik z określoną wiedzą, możliwościami lub dostępami w odniesieniu do swojego celu, jakim jest np. możliwość uzyskania sekretnego klucza pseudonimizacji. W zależności od powyższych scenariuszy może działać wewnątrz administratora, podmiotu przetwarzającego, a także zaufanej trzeciej strony,
- zewnętrzny – przeciwnik bez dostępu do sekretnego klucza lub innych właściwych informacji. Może mieć jednak dostęp do spseudonimizowanego zestawu danych i być może będzie w stanie spowodować pseudonimizację żądanych przez siebie identyfikatorów (danych wejściowych).
Przykładowe metody i techniki ataków to:
- ataki brute force (wyczerpujące wyszukiwanie i próba obliczenia funkcji pseudonimizacji),
- wyszukiwanie słownikowe (wariant ataku brute force, gdzie używa się wielu gotowych rozwiązań do sprawdzania, czy da się odwrócić pseudonimizację),
- zgadywanie, tzn. branie pod uwagę innych danych niż pseudonim (np. uwzględnienie faktu, że niektóre fragmenty pseudonimów występują częściej, lub wykorzystanie znanych atakującemu danych powiązanych z pseudonimem – jak rodzaj przeglądarki, lokalizacja użytkownika, data rejestracji itd.).
Typowe cele ataków na pseudonimizację to:
- uzyskanie sekretu pseudonimizacji (zdolności do odwrócenia pseudonimizacji),
- całkowite odwrócenie pseudonimizacji (połączenie jednego pseudonimu lub kilku z identyfikatorami),
- dyskryminacja (identyfikacja przynajmniej jednej cechy osoby, której dane dotyczą, co może wystarczyć do jej dyskryminacji).
Na skuteczność ataków wpływają następujące czynniki:
- zakres danych osobowych zawartych w pseudonimie,
- wiedza przeciwnika,
- wielkość domeny identyfikatorów,
- wielkość domeny pseudonimów,
- dobór i konfiguracja zastosowanej funkcji pseudonimizacji (także rozmiar tajnego klucza).
Oceny, czy zastosowana metoda i technika pseudonimizacji zapewnią odpowiedni poziom bezpieczeństwa, należy dokonać w ramach analizy ryzyka.
Podsumowanie
ENISA rekomenduje dążenie do najwyższego dostępnego poziomu pseudonimizacji (state-of-the-art). Podsumowując, najlepsze podejście do pseudonimizacji:
- uwzględnia całość dostępnego zestawu danych,
- zna rozmiar domen wejściowych dla poszczególnych wartości,
- stosuje pseudonimizację do wszystkich wartości tak, aby uniemożliwić ataki brute force lub słownikowe,
- eliminuje możliwość uzyskania dodatkowej wiedzy lub przeprowadzenia ataków na podstawie statystyk,
- zapewnia jedynie użyteczność konieczną dla celu przetwarzania, eliminując jakąkolwiek inną użyteczność spseudonimizowanego zestawu danych.
Decydując się na zastosowanie pseudonimizacji, koniecznie weźmy pod uwagę:
- czy przyjęta metoda spełni cele D1 i D2, opisane w artykule,
- jak zapewnimy bezpieczeństwo tajnego klucza (sekretu) pseudonimizacji, a w szczególności – oddzielenie go od zbioru danych,
- czy przyjęta metoda nie utrudni pracy (np. ze względu na zbyt długi czas odwrócenia pseudonimizacji).
Opracowano na podstawie wytycznych w zakresie technik i najlepszych praktyk pseudonimizacji i powiązanych z nimi wytycznych w zakresie kształtowania technologii w zgodzie z przepisami RODO – przegląd dotyczący pseudonimizacji danych.