
Business continuity and rapid disaster recovery are now the foundations of organisational security, particularly in the face of growing cyber threats and operational risks. The NIS2 Directive has been implemented into Polish law through an amendment to the Act on the National Cybersecurity System. This Act, known as the KSC Act, introduces new obligations for essential and important entities and requires organisations to develop and maintain a Business Continuity Plan (BCP) and a Disaster Recovery Plan (DRP).

Why ensuring business continuity is so important
Incidents may have various sources – from natural disasters to technological failures or cyberattacks. Any interruption to the operation of critical services means financial, operational and reputational losses. Business continuity planning enables organisations not only to survive a crisis, but also to operate stably in the long term.
How to create an effective business continuity plan and disaster recovery plan
-
Rely on proven standards
Developing a plan does not have to mean reinventing the wheel. It is worth using recognised international standards, such as ISO 22301 for business continuity or ITIL for incident management. This will make the measures consistent and measurable.
-
Identify threats and critical events
Create a list of potential events that may disrupt your services. Do not forget about:
- natural disasters (floods, fires),
- IT infrastructure failures,
- cyberattacks (e.g. ransomware),
- supply chain disruptions.
-
Plan recovery mechanisms
An effective plan must include specific resources and actions:
- backups – specify where the data will be stored and how often backups will be created,
- recovery testing – regularly verify the effectiveness of procedures,
- time objectives – define key indicators such as Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
What evidence of compliance is worth preparing
To demonstrate compliance with NIS2 requirements, the organisation should have the following documents:
- a business continuity plan (BCP),
- a disaster recovery plan (DRP),
- documentation confirming that the measures comply with standards or best practices,
- a list of identified threats and assigned recovery mechanisms.

What are the key elements of a business continuity plan and a disaster recovery plan
In accordance with NIS2 guidelines, an organisation's operations should be restored in line with the business continuity plan (BCP) and the disaster recovery plan (DRP). These plans must be based on the results of the risk assessment in order to effectively minimise the impact of disruptions.
A well-prepared plan should include the following elements:
-
Purpose, scope and recipients of the plan
Define the main purpose of the plan and its scope – which processes and systems it covers. Define who the intended recipients of the plan are: the management board, senior management or specific operational teams.
-
Roles and responsibilities
Indicate the persons responsible for specific stages of implementation and execution of the plan. Establish the hierarchy and the scope of responsibilities of individual members of the crisis response team.
-
Key contacts and communication channels
Prepare a list of key contacts – both internal (IT teams, management) and external (service providers, partners, regulatory authorities). Establish communication channels for use in crisis situations, such as teleconferences, secure messaging applications, or designated points of contact.
-
Conditions for Activating and Deactivating the Plan
Specify the circumstances under which the plan is triggered. Define the criteria for completing remediation activities and returning to normal operational procedures.
-
Sequence for Restoring Operations
Set priorities for actions: which systems, processes or services should be restored first in order to minimise downtime and losses. For example, critical services such as transactional systems should be restored before less essential functions.
-
Recovery Plans for Specific Operations
Develop detailed recovery plans for each key process. Define recovery objectives such as:
- Recovery Time Objective (RTO) – the time needed to restore operations,
- Recovery Point Objective (RPO) – the acceptable data loss.
-
Required Resources
Include all resources necessary for implementing the plan, including backups, redundancies, backup systems and technical support tools.
-
Restoring Business Operations and Temporary Measures
Describe the procedures for restoring normal operations after temporary solutions have been applied. Define the steps enabling a smooth transition from emergency measures to the organisation's stable operation.

PROMOTIONAL OFFER
Prepare for KSC / NIS2
Do you need support in adapting your organisation to the NIS2 requirements set out in the KSC Act? During the consultation, we will discuss your needs and propose tailored solutions
How to Effectively Implement a Business Continuity Plan and Disaster Recovery Plan
Ensuring business continuity and disaster recovery is a fundamental NIS2 requirement. ENISA guidelines emphasise the need to plan, monitor and implement advanced solutions that will enable organisations to respond quickly to incidents and minimise disruptions to access to critical services.
To comply with these requirements, the following actions should be taken:
-
Monitoring and documenting the implementation of the plan
Implementing a business continuity plan requires systematic maintenance of an implementation log. The log should describe:
- decisions made,
- steps taken in the process,
- the final time required to restore full operational capability.
Such documentation makes it possible to assess the effectiveness of the اقدامات taken and improve procedures in the future.
-
Setting priorities in the process of restoring operations
The order in which services are restored should be based on clearly defined criteria:
- classification of assets in terms of their criticality,
- the importance of services for the organisation’s functioning,
- dependencies between services – priority should be given to those services that are essential for other processes.
-
Planning resources and capacity
Appropriate performance of information processing systems, communications and environmental support systems must be ensured after the plan is activated. Key considerations include:
- ensuring the operational capability of primary and backup systems,
- cooperation with alternative telecommunications service providers.
-
Preparing for service restoration
The process of restoring services after a disruption requires specific actions, such as:
- creating backup locations (failover sites),
- securing backups of the highest-priority data at remote locations.
-
Cooperation with external providers
Services provided by third parties must be available in an emergency, e.g. through ready-to-use backup environments (hot sites).
-
Implementation of advanced recovery mechanisms
In order to increase the effectiveness of remediation measures, it is worth applying:
- full redundancy of key assets,
- failover mechanisms,
- alternative operational locations.

Examples of evidence of effective implementation of the business continuity plan and disaster recovery plan
The implementation of the business continuity plan and disaster recovery plan should be supported by specific actions and evidence of their effectiveness. The ENISA guidelines indicate which elements may demonstrate that an organisation is properly prepared.
-
Disaster recovery measures
The organisation should have mechanisms in place to enable rapid restoration of services, such as:
- backup sites (failover sites) in other regions,
- data backups stored in remote locations,
- other measures ensuring redundancy of critical assets.
-
Up-to-date organisational structures
The organisational structure should be:
- up to date,
- clearly defined,
- widely communicated throughout the organisation so that all employees know their roles and responsibilities in crisis situations.
-
Mapping dependencies between sectors and services
It is necessary to develop:
- a map of sectors and services critical to the organisation,
- contingency plans that minimise the impact of disruptions on dependent and interdependent sectors,
- risk management strategies arising from outages of networks or services.
Impact analysis of disruptions and recovery objectives
In accordance with NIS2 requirements, organizations should carry out a Business Impact Analysis (BIA) in order to assess the potential effects of major disruptions to system operations. Based on the BIA results and the risk analysis, key recovery objectives should be defined and appropriate business continuity procedures implemented.
-
Key recovery objectives (RTO, RPO, SDO)
- Recovery Time Objective (RTO) – the maximum acceptable time for restoring resources and business functions (e.g. ICT systems) after a failure occurs.
- Recovery Point Objective (RPO) – the acceptable amount of data that may be lost as a result of a disruption in the operation of specific systems or applications.
- Service Delivery Objective (SDO) – the minimum performance level that business processes must achieve when operating in contingency mode.
The values of RTO, RPO and SDO make it possible to define priorities and establish procedures for system backups and redundancy.
-
Documenting the disaster recovery plan
An effective recovery plan should include:
- defined RTO, RPO and SDO objectives,
- compliance with applicable laws and legal regulations.
-
Examples of evidence of compliance with the requirements
- Documented BIA analysis together with specified recovery objectives.
- Processes, procedures and measures ensuring the required level of business continuity in crisis situations.

Testing and updating the business continuity plan and disaster recovery plan
ENISA guidelines clearly emphasize that the business continuity plan (BCP) and the disaster recovery plan (DRP) must be regularly tested, reviewed and updated. The purpose of these activities is not only to verify their effectiveness, but also to take into account lessons learned from previous tests and significant changes in the organization's operations.
-
Regular Testing and Review of Plans
Plans should be tested at least once a year and:
- after significant incidents,
- following changes in infrastructure or risks.
The following should be taken into account during testing:
- change logs (change logs),
- previous incidents,
- results of prior tests.
-
Testing Alternative Processing Locations
As part of disaster recovery plan testing, it is necessary to:
- familiarise personnel with the operation of the facilities and resources,
- assess the ability of the alternative environment to maintain operations.
-
Testing Data Centre Infrastructure
Tests should include:
- resource availability,
- auto failover mechanisms (auto failover),
- the resilience of the infrastructure to disruptions and its ability to ensure service continuity.
-

Free GDPR knowledge.
Use it as much as you like!Webinars, articles, guides, training sessions, snippets and support. Welcome to the ODO 24 knowledge base.I'M INFull System Restoration
The objective of testing should be to restore the system to a known state. This makes it possible to confirm the effectiveness of recovery procedures.
-
Updating Plans and Actions
Based on the tests, the following should be updated regularly:
- change logs,
- operational test results,
- documentation of training outcomes and testing activities.
-
Review of Roles and Responsibilities
The roles and duties of personnel responsible for implementing business continuity plans should be periodically verified and updated.
-
Management of External Suppliers
Verification of third-party disaster recovery plans is key to ensuring compliance with the organisation's requirements.
-
Communication of Changes
Any update to business continuity plans (BCP) and disaster recovery plans (DRP) should be effectively communicated to the key members of the teams responsible for their implementation.
Examples of evidence of effective testing and updating of the business continuity plan and disaster recovery plan
Implementing and maintaining a business continuity plan (BCP) and a disaster recovery plan (DRP) requires regular testing and documentation of the results. ENISA guidelines indicate the basic examples of evidence confirming the effectiveness of these activities.
-
Documented test plans and schedules
The organisation should have:
- schedules for future tests,
- plans for regular reviews and updates.
-
Records of previous tests and reviews
Evidence of tests and reviews includes:
- results of previous tests,
- review records and updates implemented on the basis of conclusions drawn from tests.
-
BCP and DRP execution logs
Logs of business continuity plan (BCP) and disaster recovery plan (DRP) execution should contain detailed information on:
- decisions taken,
- steps carried out in the process,
- the final recovery time.
-
Communication of changes
Evidence confirming communication regarding changes to the plans should be collected, such as:
- emails,
- documents,
- intranet announcements.
-
Updates to plans and procedures
Evidence of implemented changes includes:
- updated plans, procedures and changes to workflows (workflow),
- incorporation of conclusions drawn from previous tests into current plans.
Backup Management
Proper backup management (backup management) is fundamental to maintaining business continuity and organizational resilience against disruptions. Under the KSC Act, organizations must maintain data backups and ensure adequate resources — both technical and human — to achieve the required level of redundancy.
Guidelines for Backup Management
Organizations should:
- define a redundancy strategy — decide whether to invest in their own backup solutions or use the services of external entities, such as cloud service providers,
- ensure physical separation of backups — in order to minimize the risk of data loss in the event of a local failure.

PROMOTIONAL OFFER
It is time for effective implementation of the NIS2 requirements set out in the KSC Act
Are you wondering how to comprehensively prepare your company for the new directive? During a short conversation, you will learn about the offer and receive a discount
Examples of evidence of effective backup management
- Backups are physically separated from the primary data processing systems.
- In the case of services provided by third parties, the organization has SLA agreements (Service Level Agreements) that define the service level, availability requirements, and data recovery time.
Backup Management Planning
Based on the results of the risk analysis and the business continuity plan, organizations must develop detailed backup management plans. The objective is to ensure data security, availability, and compliance with legal and operational requirements.
Elements of an Effective Backup Management Plan
-
Data Recovery Time
Defining the maximum restoration times for data and systems in line with the established recovery objectives (RTO).
-
Integrity and Accuracy of Backups
Ensuring the completeness and accuracy of backups, including configuration data and cloud-based environments.
-
Secure Storage of Backups
Backups should be stored:
- offline or online in locations outside the main network,
- at a secure distance to avoid destruction in the event of a disaster at the primary site.
-
Access Control Measures
Implementing physical and logical safeguards appropriate to the classification of assets in order to protect backups against unauthorised access.
-
Data Restoration
Developing procedures for restoring data from backups to ensure a rapid and effective recovery process.
-
Data Retention Periods
Taking into account business requirements and legal provisions in respect of data retention.
Examples of Evidence of Effective Backup Management
- Backup plans – detailed documentation of backup schedules and procedures.
- Backup software logs – confirming that backups are created regularly.
- Physical separation of backups – storing backups away from the primary location and securing them (e.g. by encryption).
- Offsite backup reports – e.g. in the cloud or in a remote data centre.
- Backup software configuration – verification that data is copied and stored on different media.
- Data restoration procedures – clear and precise instructions covering all key systems and services.
- Cloud service settings – confirmation of the configuration for receiving and storing backups.

Working with good GDPR tools is no work at all!
Verification of backup integrity
Regular integrity checks of backups are essential to ensure their reliability and readiness for data restoration in crisis situations. The NIS2 Directive sets out best practices that organisations should implement to ensure effective data protection.
Best practices for verifying backup integrity
-
Checksum algorithms (checksums) and hash functions (hashing)
Using checksums or hashing algorithms to verify that the data in backups matches the original.
-
Automating integrity tests
Implementing scripts that automatically run integrity tests to minimise the risk of human error.
-
Regular data restoration tests
Planning and carrying out regular tests involving restoring data from backups to verify their completeness and functionality.
-
Recovery scenarios
Testing various recovery scenarios, including full system restorations and recovery of individual files, to ensure that backup systems operate as expected.
-
Cloud solutions
Considering the use of cloud solutions for offsite backups, which often offer built-in integrity verification and data redundancy mechanisms.
Examples of evidence confirming effective backup verification
- Logs or reports confirming the use of checksums (checksums) or hashing algorithms.
- Settings in backup software or scripts specifying the application of data integrity verification methods.
- Records from regular tests of restoring data from backups.
- Evidence of tests of various data recovery scenarios, such as full system restoration or recovery of individual files.
- Logs of incidents in which data recovery procedures were implemented and successfully completed.
- Where third-party services are used – SLAs (Service Level Agreements) specifying requirements concerning backup integrity.
Ensuring resource availability and redundancy
Based on the results of the risk analysis and the business continuity plan, organisations must ensure resource availability by implementing at least partial redundancy. This applies to systems, resources, personnel, and communication channels.
Areas requiring redundancy
-
Network and information systems
The organisation should ensure system redundancy through solutions such as:
- using multiple Internet service providers,
- load balancing (load balancing),
- mirrored servers (mirrored servers),
- resource virtualisation,
- RAID disk arrays (Redundant Array of Independent Disks).
-
Resources and infrastructure
Redundancy should cover:
- shared workspaces,
- backup locations for data and systems,
- spare equipment,
- multiple suppliers for the same product categories in order to reduce the risk of supply disruptions.
-
Personnel and competencies
Personnel should be prepared to ensure business continuity. This can be achieved through:
- job rotation (job rotation),
- assigning backup tasks,
- conducting emergency drills (emergency drills).
-
Communication channels
It is necessary to ensure access to multiple communication platforms, such as:
- social media,
- communication applications,
- e-mail and other channels ensuring continuity of communication.
Examples of evidence of redundancy implementation
- Confirmation of the implementation of one or more of the mechanisms listed above.
- Documentation indicating operational redundancy systems and their testing (e.g. logs, test reports).

Monitoring and adjustment of resources in the context of redundancy
Organisations should ensure effective monitoring and adjustment of resources (including systems, infrastructure and personnel), taking into account redundancy and backup requirements. The key stages of this process are prioritisation and ongoing verification of available resources.
Guidelines for resource management
-
Resource prioritisation
Basing resource allocation on the results of the risk analysis to ensure their appropriate use in crisis situations.
-
Partial redundancy
Introducing redundancy in those areas where it is most important for maintaining the organisation's critical functions.
-
Diverse backup locations
Distributing backups across different locations in order to minimise the risk of data loss in the event of failures or local disasters.
-
Continuous resource monitoring
Conducting regular checks of resources in order to identify areas requiring additional redundancy or adjustment of allocation.
Examples of evidence confirming compliance
- Documentation confirming the implementation of the elements indicated within redundancy and monitoring.
- Evidence from simulations carried out and staff awareness-raising activities, assessing the organisation's readiness and the effectiveness of the procedures implemented.
Regular testing of backup recovery and redundancy
Organisations are required to carry out regular tests of backup recovery and redundancy mechanisms to ensure that these backups can be relied upon in crisis situations. The tests must cover not only data, but also the procedures and knowledge necessary to restore operations effectively. The test results should be documented, and any issues – corrected on an ongoing basis.
Guidelines for testing backups
-
Adjusting the frequency of tests to the criticality of the data
The frequency of data testing should be adjusted to their criticality:
-
high-priority data should be tested weekly,

Migrations, cloud, systems.
GDPR in IT.GDPR training in IT for Data Protection Officers (DPOs) as well as IT managers and staff. Welcome!CHECK DATES - medium- and low-priority data may be reviewed monthly,
- significant changes to data or systems should be tested immediately after implementation.
-
Analysis and updating of procedures
Conclusions from the tests should be processed by the responsible persons, and the processes and systems should be regularly updated.
-
Cooperation with suppliers and partners
External suppliers, business partners, and clients should be involved in testing recovery scenarios to ensure that all dependent components function properly.
Examples of evidence of effective testing
- Regular tests of backup status and recovery procedures.
- A backup testing programme, taking into account contingency scenarios, testing frequency, roles, and procedures.
- Test and simulation reports, including lessons learned from the actions taken.
- Documentation evidencing the performance of past tests and the remedial actions taken.
- Updated test plans, review notes, and change logs.
- Feedback from suppliers and external entities regarding improvements to test scenarios.
Crisis Management
Organizations must implement a crisis management process that enables an effective response to incidents with a significant impact on assets, operations, or reputation. The NIS2 Directive emphasizes the need to define clear criteria for escalating incidents to crisis level and to determine risk tolerance thresholds.
Criteria for identifying a crisis situation
A crisis may be declared in the event of:
- incidents posing a serious risk to key assets and operations – these are highly critical attacks, such as data breaches involving sensitive information,
- incidents significantly disrupting the organization's operational activities – causing prolonged downtime, loss of access to services, or a negative impact on customer service,
- incidents with a broad scope of impact – affecting multiple systems, departments, or locations, indicating a more serious threat,
- incidents negatively affecting the organization's reputation – which may lead to public criticism or loss of customer trust and therefore require immediate escalation,
- incidents involving advanced threats – attacks such as advanced persistent threats (APT) or organized cybercrime activity may require a response beyond standard procedures,
- incidents that may escalate – a crisis may worsen, for example where vulnerabilities allow a renewed attack or where malware spreads.
Example of evidence of effective crisis management
- The crisis management process is consistent with documented standards and best practices.
Elements of effective crisis management
Organizations must implement a crisis management process that includes elements enabling an effective response to emergencies and maintaining the security of networks and information systems.

Core Elements of the Crisis Management Process
-
Roles and Responsibilities
- Assignment of specific roles to employees, suppliers, and other entities involved in crisis response activities.
- Development of detailed procedures for each role in a crisis situation.
-
Communication
- Ensuring effective means of communication between the organisation and the relevant supervisory authorities.
- Establishing both mandatory communications (e.g. incident reports, action schedules) and non-mandatory communication methods.
-
Network and System Security
- Implementing appropriate measures to maintain the security and functionality of IT systems during crisis situations.
Guidelines on Communication in Crisis Situations
An effective communication process in crisis situations should include:
- methods of conveying information to stakeholders – defining how information will be distributed to key individuals and organisations,
- communication templates – ready-made message and crisis report templates,
- up-to-date contact details – for internal stakeholders (employees) and external stakeholders (customers, suppliers, supervisory authorities, emergency services).
Management of Information on Incidents, Threats and Remedial Measures
Organisations are required to implement a process for managing information received from computer security incident response teams (CSIRTs) or from the competent supervisory authorities. Such information may concern incidents, vulnerabilities, threats and potential remedial measures.
Key Steps in the Information Management Process
-
Designation of a Contact Point
The organisation should designate a contact point responsible for cooperation with CSIRTs. It must provide experts with appropriate knowledge in the field of incidents and threat analysis.
-
Information Classification
The information received should be classified according to categories such as:

- incidents,
- vulnerabilities,
- threats,
- remedial measures.
-
Prioritisation of information
Priority levels should be assigned appropriately to the severity of the threat and its potential impact on the organisation.
-
Verification of information
The purpose of submitting information to CSIRTs or contact teams is to verify it in terms of:
- relevance,
- urgency,
- consistency with existing logs, analytical sources and security policies.
-
Developing a remedial strategy
In the case of vulnerabilities and threats, the organisation should cooperate with the relevant teams (IT, security, operations) in order to develop and implement a risk mitigation strategy.
-
Updating incident response plans
Response plans should be updated or created anew depending on the nature and scale of the threat.
-
Communication and implementation of remedial measures
Remedial measures should be implemented, and information – communicated to the relevant stakeholders and supervisory authorities in accordance with regulatory requirements.
-
Sharing knowledge
Organisations should share findings and information about incidents with CSIRTs in order to support the wider cybersecurity community.
Example of evidence of compliance with the information management process
- Documentation from previous communication, e.g. emails, correspondence, minutes of meetings with CSIRTs or the competent supervisory authorities.
Testing and updating the crisis management plan
Organizations must regularly test, review, and update the crisis management plan. This ensures its effectiveness and alignment with evolving threats and operations. Tests should be conducted periodically and following significant incidents or operational changes.
Guidelines for testing the crisis management plan
-
Scope and frequency of tests
The crisis management plan should be subject to regular:
- full tests – conducted at least twice a year,
- stress and component tests – carried out once a year, in order to assess specific elements of the crisis management plan.
-
Testing method
The testing process should include:
- analysis of previous crises and emergency situations,
- comparison of test results with previously established recovery objectives (e.g. RTO, RPO and SDO),
- identification of areas requiring improvement and updating of crisis management procedures.
-
Updating the plan
After the tests have been completed or following significant organizational and operational changes, it is necessary to:
- update crisis management procedures,
- review network and information systems security policies.
Examples of evidence of effective testing and updating of the crisis management plan
- Documentation showing the integration of crisis management with incident response plans.
- Identified previous crises and analysis of their impact on business operations.
- Reports from crisis management plan tests, including details of test scenarios, a list of participating individuals, and the results.
- Post-test evaluation reports indicating strengths, weaknesses, and areas requiring improvement.
- Records of internal and external reviews and audits of the plan, together with conclusions and corrective actions taken.
Where should implementation of the NIS2 requirements set out in the KSC Act begin?
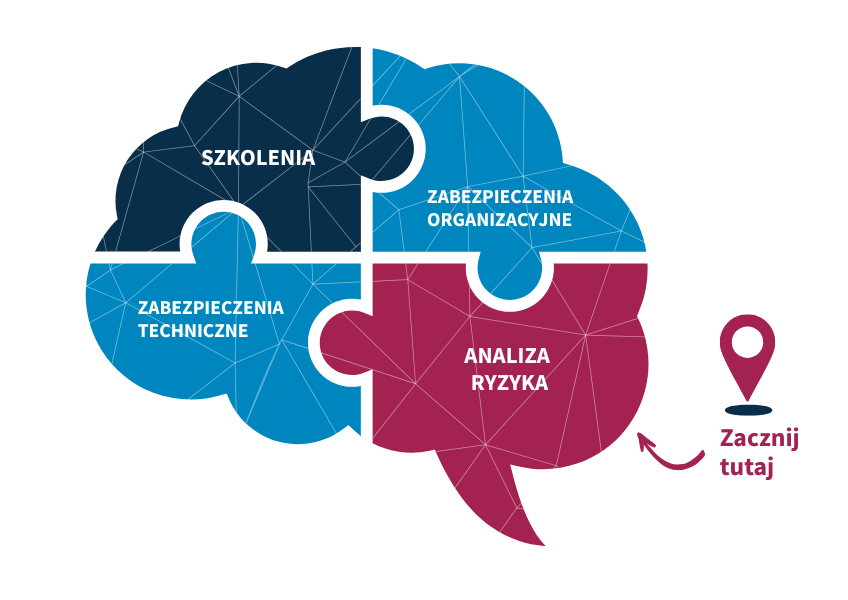
Implementation of the NIS2 requirements set out in the KSC Act should begin with a risk analysis – this is the first and key step that makes it possible to identify assets, threats, and security gaps.
Why is this so important?
NIS2, like GDPR, does not specify concrete protective measures – it is up to you, on the basis of the risk analysis you carry out, to determine appropriate security measures.
Further steps in the implementation of KSC / NIS2 are:
1. Technical safeguards
Investments in specific technologies and protective tools. NIS2 requires real, “hard” security, not just documentation.
2. Organizational safeguards
Development and implementation of procedures required under KSC / NIS2. Thanks to them, employees will know how to operate safely within the IT infrastructure.
3. Training
Regular education of employees and management board, which will ensure awareness of roles, responsibilities, and security principles. This is a direct NIS2 requirement.
In summary: start with risk analysis, and only then ensure appropriate technical and organizational safeguards and training.

