
Regardless of the scale of its operations, any organisation covered by the NIS2 obligations set out in the Act on the National Cybersecurity System (KSC) may use an incident management policy as a tool to improve risk management, increase resilience to cyber threats and enhance the level of digital security. In this article, we will examine the benefits of implementing such a policy and the elements it should contain in order to be effective and compliant with the new regulations.

Incident Management Policy
In accordance with the KSC / NIS2 Act, essential and important entities are required to develop and implement an incident management policy that clearly defines the roles, responsibilities and procedures related to incident detection, analysis, containment, response, recovery, documentation of such incidents and their timely reporting.
This policy should have clearly defined objectives and be consistent with applicable laws, regulations and industry standards, such as ISO/IEC 27001 or ENISA guidelines. It is of fundamental importance that it incorporates the standards and good practices adopted by the organisation as the basis for its operations. As part of compliance, the organisation should have a documented policy that sets out the required elements and procedures in detail. Another important aspect is the precise definition of the scope of responsibility and the assignment of roles within the organisation in order to ensure an effective incident response. A policy developed in this manner not only helps meet regulatory requirements, but also minimises the risk and potential losses arising from incidents, thereby strengthening the organisation’s resilience to cyber threats.
Incident Management Policy as a Pillar of Business Continuity and Disaster Recovery Planning
The incident management policy is a cornerstone of the information security management system. It should be consistent with the Business Continuity Plan (BCP) and the Disaster Recovery Plan (DRP). This enables organisations to respond effectively to incidents in a way that minimises their impact on operational activities and IT infrastructure. However, in order to ensure comprehensive incident management, this policy must include specific elements.
Elements of the incident management policy
- Incident categorisation system
The policy should define a consistent incident categorisation system. Such categorisation makes it possible to quickly determine the incident’s priority and appropriately adjust remediation measures.
- Communication plans, including escalation and reporting procedures
Proper communication in crisis situations is the foundation of effective incident management. The policy should include detailed communication plans that specify how and to whom incidents should be escalated, as well as setting out the rules for reporting to supervisory authorities or other relevant entities.
- Assignment of roles and responsibilities
The policy must clearly indicate which employees are responsible for detecting incidents and responding to them. It is important that these roles are assigned to competent and trained individuals who have the knowledge and tools necessary to act quickly and effectively.
- Documents supporting the incident management process
Effective incident management requires having appropriate documents, such as:
- incident response manuals – describing step-by-step procedures to follow in various scenarios,
- escalation charts – facilitating the rapid identification of the relevant individuals or teams that should be involved at a given stage,
- contact lists – enabling quick access to the details of the persons responsible for incident response,
- document templates – simplifying and expediting the incident reporting process and communication with the relevant entities.

Incident categorisation system
An important part of the incident management policy is the incident categorisation system. It should make it possible to identify the consequences of an incident and to prioritise events based on clearly defined criteria. Example criteria include:
- impact on business operations,
- data classification in accordance with the GDPR,
- legal and regulatory impact,
- scope and scale of the incident,
- type of attack (e.g. malware, ransomware),
- criticality of the affected systems,
- urgency of mitigating the effects of the incident,
- data recovery capability,
- impact on human life and safety.
Types of incidents covered by the incident management policy
The policy should cover various types of incidents, such as:
- system failure and loss of service availability,
- malicious software,
- denial of service (DoS) attacks,
- system errors and user errors,
- breaches of data confidentiality and integrity,
- misuse of network and IT systems.
Incident communication plan
Effective communication in crisis situations is essential for successful incident management. The communication plan should include:
- the purpose and scope of the plan,
- roles and responsibilities for communication tasks,
- a list of internal and external stakeholders who should be informed,
- conditions and procedures for incident escalation,
- communication channels (e-mail, intranet, telephones, social media, press releases),
- options for collecting feedback or questions from stakeholders,
- guidelines on communication deadlines and update frequency,
- ready-made message templates for various scenarios.
Key elements of an effective incident management policy in relation to business continuity and disaster recovery
An effective incident management policy should be consistently integrated with the business continuity plan (BCP) and the disaster recovery plan (DRP). Such integration enables organisations to be better prepared for a wide range of threats and to minimise their effects.
The most important elements that should be documented and implemented
- Links between the incident management policy and the BCP and DRP plans
The policy should refer to the processes and procedures set out in the business continuity plan and the disaster recovery plan. Such consistency ensures their mutual complementarity and operational coherence.
- Registers of tests and simulations
Regular tests and exercises covering both incident management processes and the business continuity plan and disaster recovery plan are essential to ensure the effectiveness of all components.
- Interviews with key personnel
Discussions with employees responsible for incident response, business continuity and disaster recovery make it possible to assess whether the policy is understood and applied in practice.
- Incident categorisation system
Every organisation should have a clearly defined incident categorisation system. Such a system enables a rapid assessment of the event’s priority and its impact on operations, and also makes it possible to identify the required actions.

- Evidence of implementation of the incident management policy
The documentation should confirm that the incident management policy has been developed, implemented and communicated to all employees.
- Incident communication plan
The organisation should have a detailed communication plan concerning incident management, including, among other things, communication channels, escalation procedures and ready-made message templates.
- Procedures for communication with the relevant authorities and CSIRT
The policy should specify the steps necessary to report an incident to the relevant regulatory authorities and computer security incident response teams (CSIRT).
- Procedures for communication with customers and suppliers
In the case of incidents that may affect clients or require the involvement of suppliers, the policy should indicate how and when they are to be informed, while ensuring transparency and operational effectiveness.
Testing and reviewing the incident management policy
Regular testing of the roles, responsibilities and procedures set out in the incident management policy is essential to maintaining their effectiveness and alignment with the current threat landscape. It is recommended that tests be conducted at least twice a year, and reviews be carried out at least once every 12 months.
Methods of testing the incident management policy
Testing the incident management policy may take various forms depending on the specific nature of the organisation and the level of risk. Among the recommended methods, the following are worth highlighting:
- tabletop exercises – an effective method for assessing the consistency of procedures and the team’s level of awareness, based on theoretical crisis simulations during which participants discuss their roles and actions step by step,
- incident simulation – a practical reenactment of an attack or crisis situation, based on identified risks and current threats, allowing the organisation’s response to be verified under realistic conditions,
- red team/blue team exercises – a scenario involving the simulation of an attack (red team) and defence (blue team), enabling testing of both incident response and the effectiveness of protective systems,
- log analysis – a review of system records in order to identify traces of potential incidents, their sources and the effectiveness of the monitoring procedures implemented,
- reconstruction of previous incidents – a step-by-step analysis of incidents that occurred in the past, enabling an assessment of the effectiveness of remedial actions and the policies implemented.
Scope of the review of roles, responsibilities and procedures
The review of roles, responsibilities and procedures should be carried out at least once a year. During the update, it is advisable to take into account:
- results of the tests carried out – an analysis of the results gathered during exercises, which makes it possible to identify areas requiring corrections or improvements,
- changes in the threat landscape – new attack techniques, evolving threats and the growing complexity of the IT environment, so that procedures can be adapted to current realities,
- legal and regulatory requirements – changes in provisions concerning network and information system security, as well as industry regulations,
- changes in organisational policies – any changes to internal security policies in order to coordinate them with incident management procedures.

PROMOTIONAL OFFER
Security Incident Management
Would you like to implement an effective incident management system in your organisation? Consult us and receive a tailored implementation proposal
Examples of evidence of effective testing and review of the incident management policy
Documenting the implementation of the incident management policy is of fundamental importance in ensuring compliance with regulatory requirements and in assessing an organisation’s readiness to respond to potential threats. The effectiveness of actions in this area may be evidenced by the following:
- documentation of periodic simulations and awareness-raising activities – regular incident simulations and staff training make it possible to assess the team’s readiness and the adequacy of the procedures used, which may be reflected in exercise reports, simulation scenarios or training schedules,
- plans and schedules for testing the incident management policy – an important element confirming the implementation of the incident management policy is documentation containing test schedules, descriptions of planned exercises and reports on the execution of tests,
- plans and schedules for reviews of the incident management policy – key evidence that the procedures are kept up to date and remain compliant with applicable requirements consists of reviews of the incident management policy carried out in accordance with an established schedule, together with the results of the analysis, conclusions and recommendations for improvements.
Collecting the above evidence makes it possible not only to verify the effectiveness of the procedures, but also to document compliance with legal regulations and security standards.
Monitoring and logging activity in IT infrastructure
Monitoring and logging activities in information systems and the organisation's networks are essential measures that make it possible to detect potential incidents and respond quickly to threats. Properly implemented monitoring procedures support both security and the optimisation of system performance.
Objectives of activity monitoring
Through activity monitoring, an organisation can achieve various objectives depending on its needs. The most important monitoring objectives include:
- threat detection – identifying unauthorised activities and potential attacks,
- compliance assurance – monitoring adherence to procedures and legal regulations,
- incident response support – recording events that may serve as a basis for swift intervention,
- performance optimisation – analysing data in order to improve the operation of systems and networks,
- anomaly detection – identifying irregular behavioural and activity patterns,
- data loss prevention (Data Loss Prevention) – monitoring activity aimed at preventing data breaches,
- network status monitoring – ongoing control of network performance and security.
Description of monitoring procedures
Procedures relating to monitoring should include:
- objectives – defining clear and measurable monitoring objectives, such as incident detection or performance improvement,
- scope of collected data – identification of what information will be monitored (e.g. system logs, network traffic, user behaviour),
- analysis of data algorithms – methods of processing and interpreting the collected data,
- notification mechanisms – establishing ways to inform the relevant persons or teams about detected incidents and irregularities.
Selection of monitoring tools
Effective monitoring requires the use of appropriate tools that meet specified criteria. When selecting them, it is worth taking into account:
- ease of use – the intuitiveness of the interface and the availability of functionality for staff,
- integration with existing systems – the possibility of connecting with the organisation's current IT infrastructure,
- minimisation of manual interventions – automation of data collection and analysis,
- ability to collect data from various sources – support for network, application or system logs,
- security features – encryption, access control and data protection mechanisms,
- costs and licensing – analysis of the costs of implementing and maintaining the tools.

Examples of evidence of monitoring and activity logging
Implementing effective monitoring and activity logging procedures requires appropriate documentation and evidence confirming the achievement of the intended objectives. Examples of such evidence include:
- existence of procedures – formal monitoring and logging procedures are in place and available to the teams responsible for security,
- monitoring and logging tools – the organisation has appropriate tools enabling the collection, analysis and reporting of activity in network and information systems,
- configuration settings – the configuration of logging functions is adapted to specific monitoring objectives, such as threat detection, performance analysis or data loss prevention,
- compliance with standards and good practices – the login function settings are consistent with the applicable standards and best practices in information security,
- log protection mechanisms – safeguards are in place to ensure the confidentiality, integrity and availability of logs, such as encryption, access control and redundancy mechanisms.
Automation of monitoring and error minimisation
Automating the monitoring of IT systems and networks is key to ensuring the effectiveness of the incident detection and response process. This process, carried out continuously or periodically, should be adapted to organisational capabilities and focused on minimising false positives and false negatives.
Guidelines for optimising monitoring
To reduce the number of false alarms and incorrectly detected incidents, it is recommended to:
- use analytical algorithms and machine learning – advanced algorithms can analyse large data sets, detect patterns and reduce the risk of misidentifying incidents,
- continuously update monitoring tools – monitoring systems should be regularly adjusted to new threats and changing conditions in the IT environment,
- optimise detection parameters and thresholds – fine-tuning monitoring settings based on current data and feedback from security teams makes it possible to improve the accuracy of incident identification.
Examples of evidence of the effectiveness of the monitoring system
Organisations may confirm the effectiveness of the implemented monitoring system through the following evidence:
- compliance with the latest technological standards – monitoring, recording and data analysis tools are consistent with best practices and the current state of technical knowledge,
- use of SIEM systems – advanced Security Information and Event Management (SIEM) systems analyse data, detect anomalies and identify deviations from established baseline patterns,
- error-reducing mechanisms – implemented solutions, such as automatic filtering and event correlation, effectively minimise false alarms and the risk of missing incidents.
Scope of logging activities in information systems
In accordance with established monitoring and logging procedures, organisations are required to maintain, document and review logs. The list of assets subject to logging should be developed on the basis of the results of the risk analysis. Depending on the needs, logs should include the following categories:
- outgoing and incoming network traffic – recording communication across the organisation’s networks for the purpose of monitoring and analysing threats,
- creation, modification and deletion of users – changes to user accounts and privilege escalations in systems and information networks,
- access to systems and applications – recording user attempts to access the organisation’s resources and activities related to such access,
- authentication-related events – recording information concerning log-in, log-out and authorisation attempts,
- privileged access – actions performed by administrative and privileged accounts in systems and applications,
- access to configuration and backup files – logging changes to critical configurations and backup files,
- logs from security tools – records from security systems such as antivirus software, IDS/IPS or firewalls,
- use of system resources – monitoring the use of resources such as the processor, memory and application performance,
- physical access to facilities – recording attempts of physical access to the organisation’s premises or devices, as well as events related to such access,
- access to network devices – logging attempts to configure network devices and use of those devices,
- log activation, stopping and pausing – recording events related to the management of logging processes,
- environmental events – monitoring information related to the environment, such as power failures or changes in operating conditions of systems.

Critical configuration and the importance of logs
Critical configurations are of key importance for the proper operation, security, and performance of an organisation’s network and information systems. Any change or incorrect configuration may lead to serious consequences. Such negative effects include, for example:
- system failure – incorrect parameters may lead to interruptions in service operation,
- security vulnerabilities – incorrect settings pose a threat to information security,
- reduced system performance – inappropriate parameters affect the stability and efficiency of network and application operation.
Examples of evidence of proper critical configuration
Evidence confirming the effectiveness of critical configuration management and logging includes at least log files containing the required elements (documenting critical changes).
Log analysis and alert thresholds
Regular log analysis and thresholds set for alerts are the most important factors in detecting anomalies and countering threats in network and information systems. Threshold values should be adjusted to the results of the risk analysis and automatically trigger alerts when exceeded, which allows for a rapid response and minimisation of potential consequences.
Guidelines for log and alert analysis
- Detection of network attacks
Detection of network attacks makes it possible to identify irregular patterns of incoming and outgoing traffic and DoS (Denial of Service) attacks in a timely manner.
- Setting alert thresholds
Threshold values should be consistent with the results of the risk analysis and take into account the most common threats. Examples of situations covered by the thresholds include:
- network traffic – sudden spikes in traffic exceeding 50% of the normal level within 10 minutes on a specified port,
- system access – three or more blocked login attempts within 15 minutes,
- privileged access – two or more privilege escalation incidents or more (e.g. changing a user account to administrator) within 24 hours,
- antivirus – three or more detections of malware on different devices or more within 30 minutes,
- system resources – three installations of unauthorised software or more within 30 minutes.
Examples of evidence of effective log and alert analysis
Organisations may demonstrate the effectiveness of implemented log and alert analysis mechanisms through the following evidence:
- regular reports – summaries of log analysis containing detected anomalies,
- configured alert thresholds – documentation of thresholds for key events and analysis of their effectiveness,
- alert activation history – records of previous instances of threshold breaches and alert triggers,
- existing incident reporting processes – confirmed escalation paths in the event of alert activation.
Storage, securing and deletion of logs
Effective log management includes defining their retention period, securing them against unauthorised access, and appropriately deleting the data after the retention period has ended.
Guidelines for log retention
- Log retention period

When was the last time
you performed a risk analysis?
- Backup logs
Backup logs must be retained for a period no shorter than the time required for log review.
- Data deletion
Data should be deleted automatically after the defined retention period has ended, in order to ensure compliance with the data minimisation principle.
Log protection mechanisms
To secure logs against unauthorised access or modification, it is recommended to implement the following mechanisms:
- encryption – protection of logs using advanced encryption techniques,
- access control – restricting the rights to read, modify and delete logs to authorized persons only,
- hashing – the use of hash functions to ensure the integrity of logs and detect unauthorized changes,
- logging access to and changes in logs – keeping detailed records of all actions related to logs (reading, modification, deletion).
Regulatory compliance
Access control and data retention mechanisms should ensure full transparency and auditability of actions.
Examples of evidence of effective log management
The implementation of appropriate log management mechanisms can be confirmed by the following evidence:
- set retention period – the defined log retention period is consistent with organizational and regulatory requirements,
- retention period complies with regulations – the log retention period is not shorter than the review period,
- centralized log management – the implemented centralized logging system enables consistent log collection and monitoring,
- no data after the retention period has elapsed – the logs do not contain data whose retention period has expired,
- access control mechanisms – safeguards restrict access to logs exclusively to authorized persons and processes.
Time synchronization and redundancy of logging systems
In order to ensure accurate log correlation and their availability, organizations must implement time synchronization mechanisms and redundancy of monitoring systems. Precisely synchronized time sources and redundant systems are necessary for effective incident analysis and minimizing the risk of data loss.
Guidelines on time synchronization
- Use of NTP and PTP protocols
The organization should use Network Time Protocol (NTP) or Precision Time Protocol (PTP) in order to synchronize time accurately between systems.
- Authenticated NTP
The use of authenticated NTP prevents time manipulation by unauthorized parties.
- Central time server
The central time server is configured so that it synchronizes with an external, reliable source and distributes time to all systems on the network.
- Multiple time sources
The use of multiple independent time synchronization sources minimizes the risk of failure caused by a single point of failure.
Guidelines on redundancy of logging systems
- Redundant log storage
Logs should be stored in redundant locations (e.g. cloud, backup servers) to prevent data loss.
- Monitoring of logging systems
Independent tools should monitor the status and availability of the main monitoring and logging systems.
- Asset inventory
All assets subject to logging should be marked in the asset register.
Examples of evidence of the effectiveness of time synchronization and redundancy of logging systems
The effectiveness of time synchronization and redundancy of logging systems may be confirmed by the following evidence:
- implemented and properly functioning log time synchronization mechanisms,
- redundant log storage in multiple locations,
- logs from tools monitoring the availability and health of the main logging and monitoring systems.
Review of procedures and the list of logged assets
Regular review of procedures and the list of logged assets subject to logging is necessary to ensure the timeliness and effectiveness of the monitoring system. Reviews should be carried out on the basis of the results of risk analysis, with particular emphasis on the criticality of the assets.
Frequency of reviews of procedures and the list of logged assets
The organisation should determine how often procedures and the list of logged assets should be reviewed, taking into account the results of the risk analysis and the criticality of individual assets. Reviews should be carried out at least once a year or following material incidents.
Examples of evidence of the effectiveness of reviews of procedures and the list of logged assets
The effectiveness of reviews of procedures and the list of logged assets may be confirmed by plans or schedules for such reviews, including the dates of their execution and their scope.
Event Reporting
Organizations should implement a simple and effective mechanism enabling employees, suppliers, and clients to report suspicious events.
Guidelines for Event Reporting
- Definition of a Suspicious Event
An event is considered suspicious if it meets one of the following criteria:
- it breaches the confidentiality, integrity, or availability of a network or information system,
- it is ongoing in nature (the event is active or persistent),
- it affects a significant number of assets, generates financial losses, or causes other consequences for the organization,
- it constitutes a breach of compliance with legal regulations or the organization's internal policies.
- Scope of Event Reporting
The organization should develop clear requirements regarding the information included in the report. The minimum scope of the report includes:
- date and time of the event,
- description of the event – including its nature and potential impact,
- evidence – screenshots, logs, or other relevant materials,
- contact details of the reporting person, provided for further communication.
- Reporting Channels
The event reporting mechanism should include various easily accessible and intuitive channels, such as:
- e-mail,
- web form,
- dedicated hotline,
- mobile application.
Examples of Event Reporting Evidence
The organization may demonstrate the effectiveness of the event reporting mechanism using the following evidence:
- documented event reporting mechanism – a formal process defining the steps for reporting security incidents,
- report templates or examples – available document templates facilitating the reporting of suspicious events,
- staff awareness – confirmation that employees know how the mechanism works and to whom suspicious events should be reported,
- multiple reporting channels – documentation confirming the availability of various communication channels, such as email addresses, web forms, telephone numbers, dedicated reporting portals.
Communication and training regarding the incident reporting mechanism
Organizations should effectively inform their employees, suppliers and customers about the incident reporting mechanism, and also provide them with regular training on the use of this mechanism.

Guidelines regarding communication and training in relation to the incident reporting mechanism
- Appropriate means and deadlines relating to incident reporting should be made available to all stakeholders (employees, suppliers, customers).
- The option of anonymous reporting should be considered in order to encourage incident reporting without fear of consequences.
- Legal obligations concerning deadlines for reporting incidents to the competent authorities should be taken into account.
- The reporting mechanism should be reinforced through various communication channels, such as newsletters, posters or other informational materials.
- Exercises and simulations should be organized to test the effectiveness of the reporting mechanism and the preparedness of staff.
Examples of evidence of effective communication and training regarding the incident reporting mechanism
The effectiveness of communication and training activities related to the incident reporting mechanism may be evidenced by:
- evidence of previous communications concerning incident reporting,
- documented communication procedures containing: the reasons for reporting incidents (business, legal), the types of events subject to reporting, the required content of communications, reporting channels, and the roles and responsibilities related to communication and incident reporting,
- training materials provided to employees, suppliers and customers,
- simulations and exercises assessing staff preparedness and the effectiveness of the incident reporting mechanism.
Assessment and classification of suspicious events
Organisations should implement mechanisms for assessing suspicious events in order to determine whether they constitute incidents and to establish their nature and severity.
Guidelines for event assessment
- Criteria for event assessment
The use of defined criteria makes it possible to assess whether a suspicious event qualifies as an incident.
- Incident classification
Determining the nature and severity of an incident should be based on a categorisation system.
Examples of evidence of effective event assessment
The following may serve as evidence of effective event assessment:
- defined criteria – formally adopted rules for assessing suspicious events,
- incident categorisation system – a mechanism enabling incidents to be classified according to their nature, scale and impact on the organisation.
Actions related to the assessment and classification of suspicious events
- Conducting the assessment
Event assessment should be carried out in accordance with previously defined criteria, with consideration given to the prioritisation of actions related to mitigating the effects and eliminating the incident (triage).
- Assessment of recurring incidents
The organisation should analyse cases of recurring incidents on a quarterly basis.
- Log review
Incident-related logs should be reviewed systematically in order to ensure an accurate assessment and classification of events.
- Log correlation and analysis process
Implementing a process that enables log correlation and analysis makes it possible to detect patterns and relationships between events, thereby supporting the effectiveness of incident assessment.
- Reassessment and reclassification of events
In the event of obtaining new information or the results of an analysis of available data, the organisation should reassess and reclassify the events in order to ensure their proper identification and prioritisation.

Procedures for assessing suspicious events and classifying incidents
Organisations should document procedures for assessing suspicious events in order to determine their nature and level of severity.
Stages of the procedure for assessing suspicious events
- Collection of information and evidence
Gathering relevant information and materials related to the event.
- Analysis of the impact of the event
Assessing the potential effects on the organisation's systems, data and operations.
- Determining the level of severity of the incident
Classifying the event on the basis of previously defined criteria.
Guidelines for incident classification and response
- Use of playbooks and runbooks
Prepared response scenarios should be developed for typical incidents such as ransomware, phishing, data loss or fire.
- Event classification
Events should be classified on the basis of:
- the level of impact – low, medium or high,
- the type of incident – e.g. malware infection, unauthorised access,
- the regulatory compliance dimension – a potential breach of legal provisions or requirements.
- Incident prioritisation
The priority of an event is determined on the basis of the criteria set out in the categorisation system.
- Identification of recurring incidents
In order to determine whether an incident is recurring, a root cause analysis is carried out.
- Review and correlation of logs
Logs should be analysed and correlated.
- Assessment of past incidents
Classification of historical incidents makes it possible to improve processes, procedures, and response thresholds.
Examples of evidence of event assessment and incident classification
An organization may demonstrate the effectiveness of the event assessment and incident classification process through the following evidence:
- documented procedures or guidelines for event assessment – a description of activities such as collecting information, conducting impact analysis, determining the severity level of the incident,
- event prioritization criteria – documentation describing the rules for classifying events based on their severity and potential impact,
- triage process – an implemented system for prioritizing alerts and reports concerning suspected events,
- playbooks for common incidents – predefined response scenarios for frequently occurring types of incidents (e.g. ransomware, phishing),
- periodic reviews of event assessment – regular analyses of historical incidents and their classification in order to improve processes, procedures, and response thresholds.
Incident response procedures
Organizations should implement procedures for effective incident response. They ensure prompt action in crisis situations in accordance with established standards.
zne dotyczące testowania procedur reag
Guidelines for incident response
- Incident Response Team (Incident Response Team)
A dedicated team should be established, consisting of employees with the appropriate technical expertise and authority to respond effectively to incidents.
- Definition of roles and responsibilities
The team should define and assign roles, such as:
- incident coordinators,
- analysts,
- persons responsible for communication and cooperation with stakeholders.
- Consideration of established standards
Incident response procedures should be developed taking into account recognized standards, e.g. ISO 27035.
Examples of evidence of effective incident response
Evidence of effective incident response includes:
- assignment of roles and responsibilities within the incident response team,
- documented standards and good practices taken into account when developing incident response procedures.
Stages of the incident response procedure
- Incident isolation

GDPR.
Support comes in handy
- Threat removal
The organisation should implement measures preventing the continuation of the incident or its recurrence.
- Incident recovery
Incident recovery, where necessary, consists in implementing processes restoring the organisation's normal operations.
Guidelines for detailed incident response procedures
- Development of detailed incident response procedures
Clear and precise procedures for dealing with various types of incidents should be prepared.
- Consideration of organisational priorities
When handling cybersecurity incidents, the organisation's priorities and the impact of the specific incident should be taken into account.
- Resolving priority conflicts
Proper incident response requires balancing between:
- measures to preserve evidence in a manner that ensures its reliability and admissibility in investigations or legal proceedings.
- reactive measures to eliminate existing threats,
- IT operational measures aimed at minimising the impact of the incident.
Decisions concerning conflict resolution should be presented to management bodies.
Examples of evidence of effective incident response
The effectiveness of incident response can be assessed on the basis of the following evidence:
- incident response procedures – documentation containing detailed steps, incident types, roles and responsibilities, management and escalation actions,
- records relating to the resolution of priority conflicts during previous incidents.
Incident communication plans and procedures
Organisations should develop detailed incident communication plans and procedures to ensure proper notification of the relevant entities and stakeholders.
Guidelines for incident communication
- Communication with CSIRT and competent authorities
Procedures should specify how to report incidents to computer security incident response teams (CSIRT) and, where necessary, to the competent supervisory authorities and competent authorities.
- Communication with stakeholders
Communication plans must take into account internal and external stakeholders, including:
- key employees,
- business partners,
- customers,
- suppliers, where their involvement is necessary.
- Contact information
Procedures should include up-to-date contact details for key individuals, external stakeholders and the competent authorities.
Examples of evidence of effective incident communication
Effective communication during incidents may be documented by:
- communication procedures specifying how to report incidents to competent authorities and CSIRT,
- communication procedures with customers and suppliers, indicating when and how to involve them.
Recording incident response activities
Organizations should maintain a detailed record of actions taken as part of incident response in accordance with applicable procedures.
Incident logs should contain at least the following information:
- the timing of individual stages – detection, isolation, threat eradication,
- the point at which systems were restored to full functionality,
- indicators of compromise (IoCs) – evidence confirming the breach,
- the root cause – analysis of the reason the incident occurred,
- actions taken at each phase – detection, isolation and eradication,
- assessment of the incident’s impact on the organization,
- communication conducted during the incident response,
- findings and recommendations arising from the incident analysis,
- incident reporting to CSIRT or the competent authorities.
Examples of evidence of incident response activities
Evidence of actions taken in connection with incident response may include incident logs, i.e. detailed records documenting the course of a given incident and the key moments of the response to that incident.
Testing incident response procedures
Organizations should regularly test their incident response procedures to ensure that they are effective and adequately prepared for different types of threats.

Guidelines for testing incident response procedures
- Testing frequency
Incident response procedures should be tested at least once a year.
- Types of incidents tested
Test scenarios should cover different types of incidents, such as:
- ransomware,
- phishing,
- data breach (data breach),
- DoS (Denial of Service) attacks.
- Stakeholder involvement
Tests should involve employees from different departments and external stakeholders, such as service providers or business partners.
- Management involvement
The management board should participate in the tests to understand its role during an actual incident.
- Evaluation of test results and updating procedures
After the tests have been completed, a review of the results should be conducted in order to draw conclusions and implement the necessary improvements to the procedures.
Examples of evidence of effective testing of incident response procedures
Evidence demonstrating the effective testing of incident response procedures includes, among other things:
- test plans and schedules – documentation of planned incident response tests,
- records of tests conducted – detailed reports on tests of various types of incidents, including conclusions and recommendations.
Post-incident reviews and root cause analysis
After remedial actions related to an incident have been completed, organisations should conduct post-incident reviews to identify the root causes, factors contributing to the occurrence of the incident, and opportunities for process improvements.
Guidelines for post-incident reviews
- Defining the post-incident review process
A process for conducting reviews after security incidents have been completed should be developed and implemented.
- Identification of root causes
The analysis should include:
- root causes,
- factors contributing to the occurrence of the incident,
- areas requiring improvements in incident detection, response to the incident, and recovery after the incident.
- Investigation of significant incidents
For major incidents, final reports should be prepared, containing:
- description of the actions taken,
- recommendations aimed at preventing similar incidents in the future.
- Documenting conclusions
The conclusions from the reviews should be documented on the basis of logs and analyses of the actions taken as part of the incident response.
Examples of evidence of effective post-incident reviews
The effectiveness of a post-incident review can be demonstrated by:
- root cause analyses – documents identifying the cause of the incident,
- reports on the handling of material incidents – detailed descriptions of the actions taken and recommendations for the future,
- documented conclusions and lessons learned from incidents – reports containing areas for improvement and good practices to be implemented.

Analysis of post-incident reviews and implementation of improvements
Organisations should confirm that post-incident reviews contribute to improving the approach to network and information security, risk management activities, and procedures related to incident handling, detection and response.
Guidelines for analysing post-incident reviews and improvements
- The results of post-incident reviews should be analysed in order to identify gaps and weaknesses in the organisation’s security system.
- It should be ensured that the identified issues are taken into account in the risk assessment process and in risk management plans.
- It should be assessed whether the existing risk management measures were effective in preventing or mitigating the effects of the incident.
- Complete review reports should be prepared, containing conclusions and recommendations for the future.
- It should be verified whether information security requirements were met during incident handling and, where necessary, appropriate corrective actions should be taken.Examples of evidence of effective post-incident analysis
Evidence demonstrating that a thorough post-incident analysis has been carried out includes, for example:
- post-incident review reports – documenting findings, identified gaps and recommendations for improvements,
- communicating corrective actions – analysis, solutions and remedial measures conveyed to the relevant team members.
Regular post-incident review assessments
Organizations should carry out regular post-incident review assessments to evaluate whether incidents resulted in appropriate analyses and conclusions and whether corrective actions have been implemented.
Guidelines for post-incident review assessments
Annual reviews or reviews following significant incidents should be conducted to verify:
- whether a post-incident review was carried out,
- which findings and recommendations resulted from the review,
- whether the identified improvements have been implemented.
Examples of evidence of effective post-incident review assessments
Evidence that an organization effectively analyses and evaluates conducted post-incident reviews includes documented plans or schedules for future reviews, confirming their regularity and planning.
Where should you start with implementing the KSC / NIS2 Act?
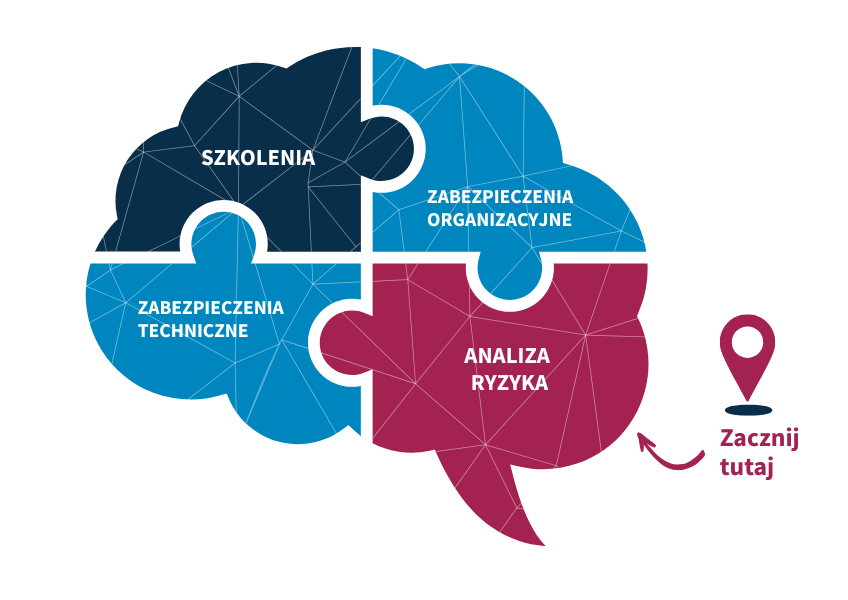
Implementing KSC / NIS2 should begin with a risk analysis – this is the first and key step that makes it possible to identify assets, threats and security gaps.
Why is this so important?
The NIS2 requirements set out in the KSC Act, similarly to the GDPR, do not specify particular protective measures – based on the risk analysis you carry out, you must determine appropriate security measures.
The next steps in implementing KSC / NIS2 are:
1. Technical safeguards
Investment in specific technologies and protective tools. The KSC / NIS2 Act requires real, „hard" security, not just documentation.
2. Organisational safeguards
Development and implementation of procedures required by KSC / NIS2. Thanks to them, employees will know how to act safely within the IT infrastructure.
3. Training
Regular training for employees and the management board, ensuring awareness of roles, responsibilities and security rules. This is a direct requirement of KSC / NIS2.
In summary: start with a risk analysis, and only then ensure appropriate technical and organizational safeguards and training.

